Все на одній сторінці
Content from Запуск та завершення роботи
Останнє оновлення 2026-06-18 | Редагувати цю сторінку
Огляд
Питання
- Як запустити програми Python?
Цілі
- Запуск серверу JupyterLab.
- Створення нового скрипту Python.
- Створення блокноту Jupyter.
- Завершення роботи сервера JupyterLab.
- Розуміння різниці між скриптом Python і блокнотом Jupyter.
- Створення в блокноті комірок типу Markdown.
- Створення та виконання в блокноті комірок Python.
Для роботи з Python, протягом цього семінару ми будемо використовувати [блокноти Jupyter][jupyter] у середовищі JupyterLab. Блокноти Jupyter широко застосовуються з метою аналізу та візуалізації даних, а також є зручним інструментальним засобом для запуску коду на Python в інтерактивному режимі, де ми можемо легко переглядати результати його виконання, та ділитися нашим кодом з іншими.
Існують й інші способи редагування, організації та виконання коду. Розробники програмного забезпечення часто використовують інтегроване середовище розробки (IDE), подібне до PyCharm або Visual Studio Code або текстові редактори такі як Vim або Emacs, щоб створити та відредагувати свої програми Python. Після редагування та збереження ваших програм Python ви можете виконувати ці програми в самому IDE або безпосередньо в командному рядку. На відміну від цього, блокноти Jupyter дозволяють відразу переглянути результати нашого Python коду.
JupyterLab має декілька інших зручних функцій:
- Ви можете легко вводити, редагувати, копіювати та вставляти блоки коду.
- Автодоповнення за допомогою клавіші Tab дозволяє легко отримувати доступ до назв об’єктів, які ви використовуєте.
- Дозволяє легко доповнювати свій код посиланнями, текстом різного розміру, маркерами тощо, щоб зробити його доступнішим для вас і ваших колег.
- Дозволяє розміщувати графічні елементи безпосередньо поруч із кодом, який їх створює, щоб продемонструвати повну історію аналізу даних.
Кожен блокнот містить одну або кілька комірок, що містять код, текст або зображення.
Початок роботи з JupyterLab
JupyterLab є сервером застосунків із вебінтерфейсом користувача від Project Jupyter, що дозволяє працювати з документами та іншими застосунками, такими як блокноти Jupyter, текстові редактори, термінали, і навіть спеціальні компоненти, гнучким, інтегрованим і розширюваним способом. JupyterLab потребує досить сучасний браузер (в ідеалі – поточна версія Chrome, Safari або Firefox); Internet Explorer версії 9 і нижче не підтримується.
JupyterLab є частиною інсталяційного пакета Anaconda Python. Якщо ви не встановили дистрибутив Anaconda Python, дивіться інструкції щодо процесу інсталяції тут.
На цьому уроці ми запустимо JupyterLab локально на наших власних пристроях, тому для цього підключення до Інтернету буде потрібно лише на початку для завантаження та встановлення середовищ розробки Anaconda та JupyterLab
- Запустіть сервер JupyterLab на вашому комп’ютері
- Використовуйте веббраузер для відкриття спеціальної локальної URL-адреси для з’єднання з сервером JupyterLab
- Сервер JupyterLab виконує обчислювальну роботу, а веббраузер відображає її результат
- Введіть код у браузері, і як тільки сервер JupyterLab завершить виконання, ви зможете переглянути результати
JupyterLab? А чому не Jupyter Notebook?
JupyterLab є подальшим кроком в еволюції Jupyter Notebook. Якщо ви використовували Jupyter Notebook раніше, то ви добре зрозумієте діапазон можливостей JupyterLab.
Досвідчені користувачі блокнотів Jupyter, зацікавлені у більш детальному обговоренні схожостей і відмінностей між інтерфейсами JupyterLab і Jupyter Notebook, можуть знайти більше інформації у документації з інтерфейсу користувача JupyterLab.
Початок роботи з JupyterLab
Ви можете запустити сервер JupyterLab через командний рядок або через застосунок, що має назву ‘Anaconda Navigator’. JupyterLab є частиною інсталяційного пакета Anaconda Python.
macOS - командний рядок
Для запуску сервера JupyterLab вам потрібно отримати доступ до командного рядка через Terminal. Існує два способи відкрити термінал на Mac.
- У каталозі Applications відкрийте підкаталог Utilities і двічі натисніть Terminal
- Натисніть Command + spacebar для запуску
Spotlight. Введіть
Terminal, а потім двічі клацніть на результаті пошуку або натисніть Enter
Після запуску Terminal введіть команду для запуску сервера JupyterLab.
Користувачі Windows - Командний рядок
Для запуску сервера JupyterLab вам потрібен застосунок Anaconda Prompt.
Натисніть Windows Logo Key і знайдіть
Anaconda Prompt, натисніть на результат пошуку або на
клавішу enter.
Після запуску Anaconda Prompt введіть команду:
Anaconda Navigator
Для запуску серверу JupyterLab з Anaconda Navigator ви маєте спочатку
запустити
Anaconda Navigator (натисніть для докладних інструкцій з macOS, Windows
та Linux). Ви можете виконати пошук Anaconda Navigator через
Spotlight на macOS (Command + spacebar),
скористатися функцією пошуку Windows (клавіша Windows Logo)
або відкривши термінал та виконавши команду
anaconda-navigator у командному рядку.
Після того, як ви запустили Anaconda Navigator, натисніть кнопку
Launch під JupyterLab. Можливо, вам знадобиться продивитись
список донизу, аби знайти її.
Нижче наведено скриншот сторінки Anaconda Navigator, схожої на ту, яка має відкриватися для macOS або Windows.

Нижче наведено скриншот екрана стартової сторінки JupyterLab, схожої на ту, яка має відкритися у вашому веббраузері за замовчуванням після запуску сервера JupyterLab в операційній системі macOS або Windows.
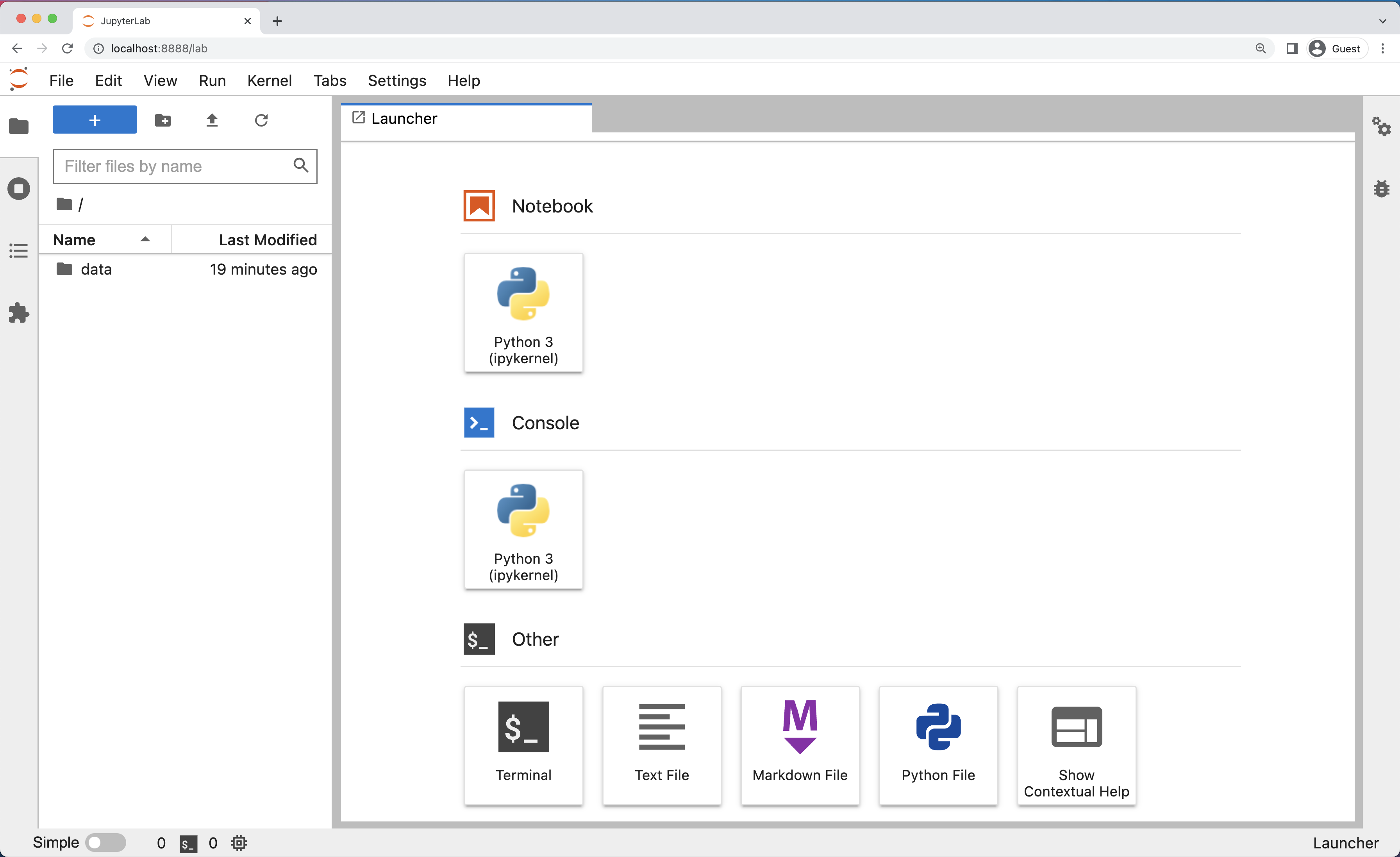
Інтерфейс JupyterLab
JupyterLab має багато функцій, які можна знайти в традиційних інтегрованих середовищах розробки (IDE), але його особливістю є забезпечення гнучких “будівельних блоків” для інтерактивних дослідницьких обчислень.
Інтерфейс JupyterLab складається з панелі меню, лівої бічної панелі (що згортається за потреби), і основної робочої області, яка містить вкладки з документами та різними застосунками JupyterLab.
Панель меню
Панель меню у верхній частині вікна JupyterLab містить меню верхнього рівня, яке зображує різні дії доступні в JupyterLab разом із їхніми комбінаціями клавіш (де це можливо). Наступні пункти меню наявні за замовчуванням.
- File: Дії, пов’язані з файлами та каталогами, такі як New, Open, Close, Save тощо. Меню File також містить дію Shut Down, яка застосовується для завершення роботи сервера JupyterLab.
- Edit: Дії, пов’язані з редагуванням документів та іншими видами діяльності, такими як Undo, Cut, Copy, Paste тощо.
- View: Дії, які змінюють зовнішній вигляд інтерфейсу JupyterLab.
- Run: Дії для запуску коду в різних застосунках, таких як Jupyter Notebook та командний рядок (розглянуто нижче).
- ** Kernel:** Дії щодо управління ядрами. Ядра у Jupyter будуть детально описані нижче.
- Tabs: Список відкритих документів та застосунків у робочій області.
- Settings: За допомогою цього меню можна налаштувати загальні параметри JupyterLab. Окрім того, у ньому також є опція Advanced Settings Editor, яка забезпечує більш детальний контроль параметрів і опцій для конфігурації JupyterLab.
- Help: Список посилань на довідку JupyterLab та інші ресурси.
Ядра
Документація JupyterLab визначає ядра як “окремі процеси сервера, що виконують ваш код у відповідних мовах програмування та середовищах.” Коли ми відкриваємо Jupyter Notebook, то ініціалізується ядро - процес, який буде виконувати код. У цьому уроці ми будемо використовувати ядро ipython, яке дозволяє запускати Python 3 в інтерактивному режимі.
Використання інших ядер Jupyter для інших мов програмування дозволить нам використовувати спільний інтерфейс JupyterLab для того, щоб писати та виконувати код, наприклад, у таких мовах як R, Java, Julia, Ruby, JavaScript, Fortran, тощо.
Скриншот стандартної панелі меню надано нижче.

Ліва бічна панель
Ліва бічна панель містить ряд найбільш використовуваних вкладок, а саме: браузер файлів (відображає вміст каталогу, де був запущений сервер JupyterLab), перелік активних ядер і терміналів, панель команд і список відкритих вкладок в основній робочій області. Скриншот стандартної лівої бічної панелі наведений нижче.
Ліву бічну панель можна згорнути або розгорнути вибравши пункт “Show Left Sidebar” у меню View, або натиснувши на активну вкладку бічної панелі.
Основна робоча область
Основна робоча область в JupyterLab дозволяє упорядковувати документи (блокноти, текстові файли та ін.) та інші види застосунків (термінали, інтерфейси командного рядка тощо) у панелі вкладок. Ці панелі можна зменшити/збільшити або поділити на підрозділи. Скриншот стандартної основної робочої області наведено нижче.
Якщо Ви не бачите вкладку Launcher на панелі запуску, натисніть синій плюс під “File” та “Edit” у панелі меню, і ця вкладка з’явиться.
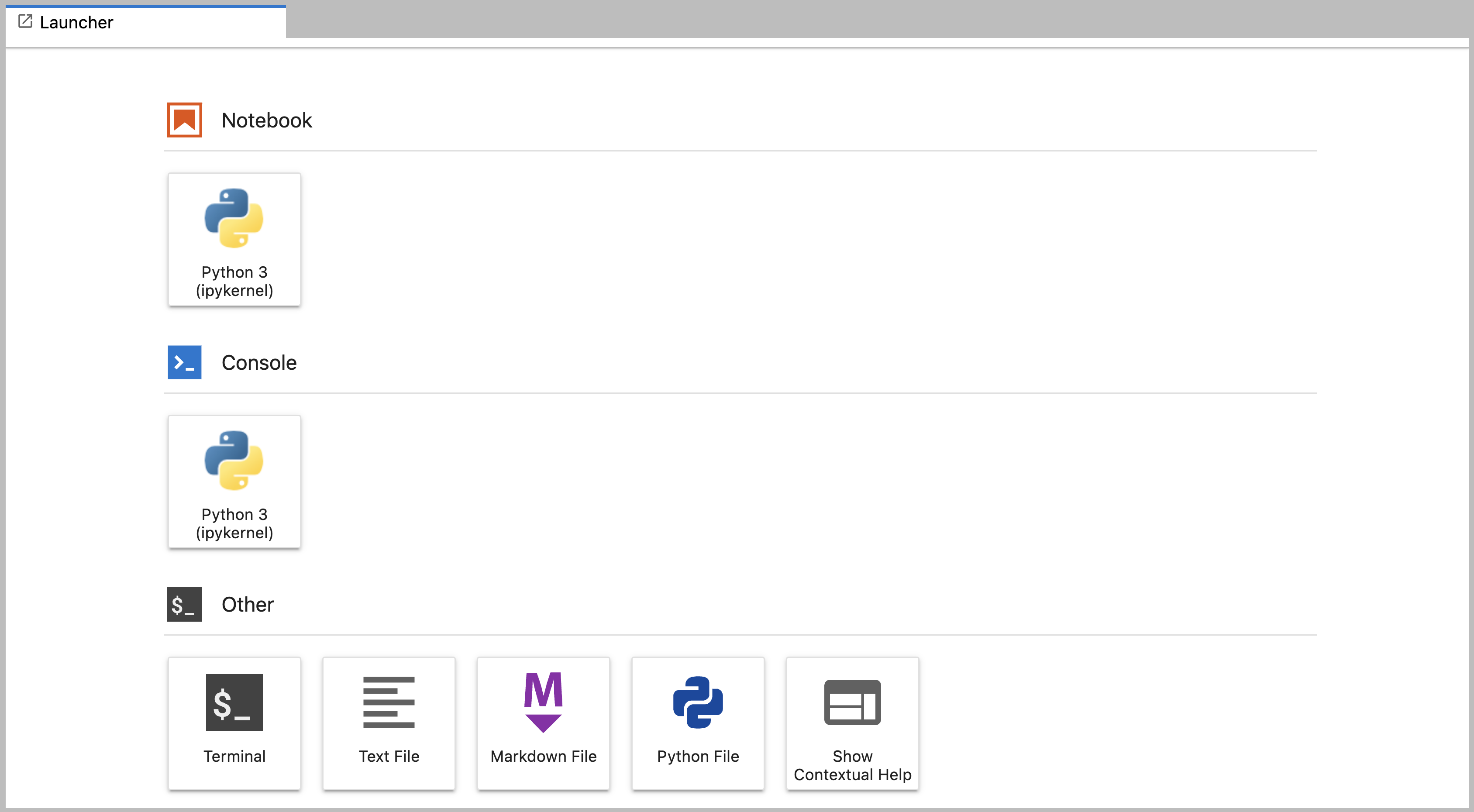
Щоб перемістити вкладку на деяку панель, перетягніть її в центр цієї панелі. Також ви можете розділити панель вкладок, перетягнувши потрібну вкладку ліворуч, праворуч, догори або донизу панелі. Кожна робоча панель має одну поточну активну вкладку. Вкладка для поточної дії позначена кольоровою верхньою рамкою (за замовчуванням - синьою).
Створення скрипту Python
- Щоб почати писати нову програму на Python, натисніть піктограму
текстового файлу під заголовком Other на вкладці Launcher
(Запуск) головної робочої області.
- Можна також створити новий текстовий файл, якщо обрати New -> Text File у меню File на панелі меню.
- Щоб перетворити цей звичайний текстовий файл на програму Python,
виберіть дію Save File As у меню File на панелі меню
та надайте новому текстовому файлу назву, яка закінчується розширенням
.py.- Розширення
.pyповідомляє всім (операційній системі включно), що цей текстовий файл є програмою Python. - Це умовність, а не вимога.
- Розширення
Створення блокноту Jupyter
Щоб відкрити новий блокнот, натисніть піктограму Python 3 під заголовком Notebook на вкладці Launcher в у головній робочій області. Ви також можете створити новий блокнот, обравши New -> Notebook у меню File на панелі меню.
Додаткові зауваження щодо блокнотів Jupyter.
- Файли, створені в Jupyter Notebook, мають розширення
.ipynb, щоб відрізнити їх від програм на Python, створених як звичайний текстовий файл. - Блокноти можна експортувати як скрипти Python, які можна запускати з командного рядка.
Нижче наведено скриншот Jupyter Notebook, який був відкритий в JupyterLab. Якщо вам цікаві подальші деталі, дивіться офіційну документацію до Jupyter Notebook.
Як це зберігається
- Файл блокноту зберігається у форматі JSON.
- Подібно до вебсторінки, те, що зберігається, відрізняється від того, що ви бачите у своєму браузері.
- Але формат JSON дозволяє Jupyter комбінувати вихідний код, текст і графіку в одному файлі.
Упорядкування документів в панелях вкладок
У головній робочій області JupyterLab ви можете впорядковувати документи на панелі вкладок. Нижче наведено приклад з офіційної документації.
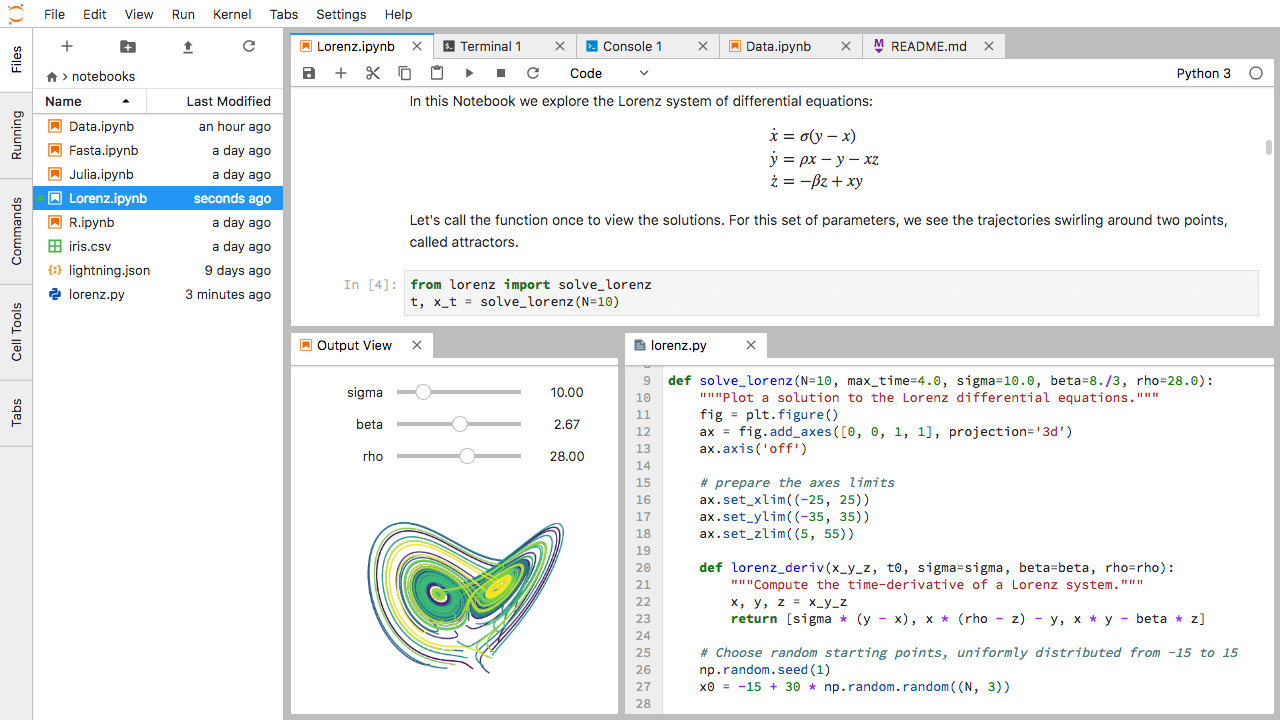
Спочатку створіть текстовий файл, консоль Python, та вікно терміналу і розташуйте їх у три панелі в основній робочій області. Далі створіть блокнот, вікно терміналу, та текстовий файл і розподіліть їх на три панелі в основній робочій зоні. Нарешті, створіть власну комбінацію панелей і вкладок. Яка, на вашу думку, комбінація панелей та вкладок буде найбільш корисною для вашого робочого процесу?
Після створення необхідних вкладок ви можете перетягнути одну з них в центр панелі для переміщення вкладки на панель; потім ви можете розділити панель, перетягнувши вкладку ліворуч, праворуч, вгору або до низу панелі.
Код або текст?
Jupyter дозволяє змішувати код і текст у різних типах блоків, які називаються комірками. Термін “код” зазвичай використовується для позначення вихідного коду програмного забезпечення, написаного будь-якою мовою програмування. “Комірка коду” в Notebook містить код; а “текстова комірка” - звичайний текст, який відображується, але не виконується.
Jupyter Notebook має командний режим та режим редагування.
- Якщо ви натиснете Esc та Return по черзі, то зовнішня межа комірки коду буде змінюватися з сірої на синю.
- Існують сірий - Command (командний) та синій - Edit (редагування) режими вашого блокноту.
- Командний режим дозволяє операції з комірками на рівні блокнота, а режим редагування змінює вміст комірок.
- В командному режимі (esc/сірий),
- Клавіша b створює нову комірку нижче поточної обраної комірки.
- Клавіша a створює одну комірку вище поточної.
- Клавіша x видаляє поточну комірку.
- Клавіша z скасовує вашу останню операцію з коміркою (це може бути операція видалення, створення тощо).
- Усі дії можна виконувати за допомогою меню, але є багато комбінацій клавіш для прискорення процесу.
Командний режим або режим редагування
Чи ви зараз перебуваєте в командному режимі чи режимі редагування на
сторінці Jupyter Notebook?
Перейдіть з одного режиму в інший, а потім у зворотному напрямку.
Використайте відповідні швидкі клавіші для видалення комірки.
Використайте швидкі клавіші, щоб видалити комірку. Нарешті, скасуйте
останню операцію над коміркою також за допомогою швидких клавіш.
Командний режим має сіру рамку, а режим редагування — синю. Використовуйте Esc та Return для перемикання режимів. Ви маєте бути в командному режимі (Натисніть Esc якщо ваша комірка синя). Введіть b або a. Ви маєте бути в командному режимі (Натисніть Esc якщо ваша клітинка синя). Введіть x. Ви маєте бути в командному режимі (Натисніть Esc якщо ваша комірка синя). Введіть z.
Використовуйте клавіатуру та мишу для виділення та редагування комірок.
- Якщо натиснути клавішу Return, рамка стане синьою та ввімкнеться режим редагування, що дозволяє введення команди в комірку.
- Якщо є необхідність введення кількох рядків кода в одну клітинку, то натискання клавіші Return в режимі редагування (синя рамка) переміщує курсор на наступний рядок в комірці, як у текстовому редакторі.
- Якщо нам потрібно запустити код, що знаходиться в комірці, нам потрібен інший спосіб повідомити про це Notebook.
- Одночасне натискання клавіш Shift + Return призведе до виконання вмісту комірки.
- Зверніть увагу, що клавіші Return та Shift розташовані поруч на клавіатурі справа.
Jupyter Notebook підтримує мову розмітки текстів Markdown.
- Блокноти також можуть візуалізувати Markdown.
- Простий текстовий формат для створення списків, посилань та інших елементів, які можуть бути використані на вебсторінці.
- Власне, це підмножина HTML, яка виглядає у стилі старомодного електронного листа.
- Перетворіть поточну комірку на комірку Markdown, увійшовши в командний режим (Esc/gray) та натиснувши клавішу M.
- Позначка
In [ ]:зникне, щоб показати, що це вже не комірка коду, і ви зможете писати текст у форматі Markdown. - Перетворіть поточну комірку на комірку з кодом, увійшовши в командний режим (Esc/gray) та натиснувши клавішу y.
Markdown робить більшість того, що можна зробити у HTML.
Таблиця: Елементи синтаксису Markdown та їх зображення.
| Код Markdown | Відображений результат |
|---|---|
|
|
|
|
|
|
|
Заголовок першого рівня |
|
Заголовок другого рівня (тощо) |
|
Переноси рядків не мають значення. Але порожні рядки створюють нові абзаци. |
|
Посилання створюються за
допомогою |
Створення списків в Markdown
Створіть вкладений список в Markdown-комірці блокноту так, щоб вона виглядала наступним чином:
- Знайти фінансування.
- Виконати роботу.
- Провести експеримент.
- Зібрати дані.
- Провести аналіз.
- Написати статтю.
- Опублікувати.
Це завдання поєднує як нумерований, так і маркований списки. Зверніть увагу, що маркований список має відступ на 2 пробіли, щоб він не збігався з елементами нумерованого списку.
1. Get funding.
2. Do work.
* Design experiment.
* Collect data.
* Analyze.
3. Write up.
4. Publish.Зміна типу вже наявної комірки з Code на Markdown
Що станеться, якщо Ви напишете у комірці код Python, а потім перемкнете її у режим Markdown? Наприклад, напишіть наступний вираз в комірці коду:
Потім запустіть цей код в комірці за допомогою Shift+Return, щоб переконатися, що ця комірка працює як комірка коду. Тепер поверніться до комірки та натисніть Esc, а потім m, щоб перемкнути комірку на Markdown і “запустити” її за допомогою Shift+Return. Що сталося, і як це може бути корисним?
Рівняння
Стандартний Markdown (наприклад, такий, що використовується для цих нотаток) не відображає рівняння, але Notebook буде це робити. Створіть нову комірку Markdown і введіть наступне:
$\sum_{i=1}^{N} 2^{-i} \approx 1$(Мабуть, це легше скопіювати та вставити.) Що зображається? Як ви
думаєте, що роблять підкреслювання _, циркумфлекс
^ і знак долара $?
Рівняння зображується у блокноті відповідно до синтаксису, який
використовується у LaTeX. Знаки долара $ використовуються
для того, щоб повідомити Markdown про те, що текст між цими знаками є
рівнянням LaTeX. Якщо ви не знайомі з LaTeX, підкреслення _
використовується для підрядкових індексів та циркумфлекс ^
використовується для верхніх індексів. Пара фігурних дужок
{ та } використовується для групування тексту
разом, щоб вираз i=1 став нижнім, а N -
верхнім індексом. Аналогічно, вираз -i взятий у фігурні
дужки, щоб зробити цей вираз верхнім індексом для 2.
\sum та \approx є командами LaTeX для значень
“sum over” й “approximate”.
Вихід з JupyterLab
- На панелі меню оберіть меню “File” і натисніть “Shut Down” внизу спадного меню. Вам буде запропоновано підтвердити, що Ви бажаєте вимкнути сервер JupyterLab (не забудьте зберегти свою роботу!). Натисніть “Shut Down”, щоб вимкнути сервер JupyterLab.
- Щоб перезапустити сервер JupyterLab, вам потрібно буде повторно виконати наступну команду в терміналі.
$ jupyter labВихід з JupyterLab
Потренуйтеся закривати та перезапускати сервер JupyterLab.
- Скрипти Python - це звичайні текстові файли.
- Застосування Jupyter Notebook для редагування та запуску Python
- Jupyter Notebook має командний режим та режим редагування.
- Використовуйте клавіатуру та мишу для виділення та редагування комірок.
- Notebook підтримує мову розмітки текстів Markdown.
- Markdown робить більшість того, що можна зробити у HTML.
Content from Змінні та присвоєння
Останнє оновлення 2026-06-18 | Редагувати цю сторінку
Огляд
Питання
- Як я можу зберігати дані в програмах?
Цілі
- Створення програм, які присвоюють скалярні значення змінним і виконують обчислення з цими значеннями.
- Відстеження у програмах значень змінних, які використовують скалярне присвоєння.
Використовуйте змінні для зберігання значень.
Змінні - це імена значень.
-
Імена змінних
- можуть складатися тільки з букв, цифр та
підкреслення
_(яке звичайно використовується, щоб відокремити слова у довгих назвах змінних) - не можуть починатися з цифри
-
залежать від регістру (тобто
age,AgeтаAGE- це три різні змінні)
- можуть складатися тільки з букв, цифр та
підкреслення
Ім’я змінної має бути змістовним, щоб ви або інший програміст знали, що це таке
Імена змінних, які починаються з підкреслення, наприклад
__alistairs_real_age, мають специфічне значення, тому ми не будемо цього робити, доки не зрозуміємо прийняті в мові Python домовленості.У Python символ
=використовується для присвоєння значення, яке знаходиться праворуч, до його імені, яке вказано ліворуч.Змінна створена, коли їй присвоюється значення.
-
У виразі нижче Python призначає вік змінній
ageта ім’я в лапках - зміннійfirst_name.
Використовуйте print для виведення значень.
- Python має вбудовану функцію
print, яка друкує щось як текст. - Щоб викликати функцію (тобто, щоб виконати її), треба вказати її ім’я.
- Щоб передати функції значення (тобто дані для друку), їх треба помістити у дужки.
- Щоб направити до друку рядок тексту, його треба помістити в одинарні або подвійні лапки.
- Значення, які передаються до функції, називаються аргументами
ВИВІД
Ahmed is 42 years old-
printавтоматично додає пробіл між надрукованими аргументами, щоб відокремити їх. - Також
printпереходить на новий рядок після друку.
Змінні мають бути створені перед їх використанням.
- Якщо змінна ще не існує, або якщо ім’я було неправильно написано, Python повідомляє про помилку. (На відміну від деяких інших мов, які можуть “вгадати” якесь значення за замовчуванням.)
ПОМИЛКА
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-1-c1fbb4e96102> in <module>()
----> 1 print(last_name)
NameError: name 'last_name' is not defined- Останній рядок у повідомленні про помилку є найбільш інформативним.
- Ми більш детально розглянемо повідомлення про помилки пізніше.
Змінні зберігаються між комірками
Майте на увазі, що в блокноті Jupyter важливий порядок виконання комірок, а не порядок їх розташування. Python запам’ятає весь код, який було виконано раніше, у тому числі всі змінні, які ви визначили, незалежно від порядку в блокноті. Тому, якщо ви визначите змінні нижче в блокноті, а потім (повторно) запустите комірки вище, то ті комірки, що визначені нижче, все одно будуть присутні. Як приклад, створіть дві комірки наступного вмісту у такому порядку:
Якщо виконати це послідовно, то перша комірка дасть помилку. Однак,
якщо ви запустите першу комірку після другої, вона виведе на
екран 1. Щоб уникнути плутанини, можна скористатися опцією
Kernel -> Restart & Run All, яка
перезавантажує інтерпретатор і запускає все з чистого аркуша, зверху
вниз.
Змінні можна використовувати для обчислень.
- Ми можемо використовувати змінні в обчисленнях так само, як би вони
були значеннями.
- Пам’ятайте, ми присвоїли значення
42зміннійageкількома рядками вище.
- Пам’ятайте, ми присвоїли значення
ВИВІД
Age in three years: 45Використовуйте індекс, щоб отримати один символ із рядка.
- Символи (окремі літери, цифри тощо) у рядку є впорядкованими.
Наприклад, рядок
'AB'не те саме, що'BA'. Завдяки такому упорядкуванню ми можемо розглядати рядок як список символів. - Кожна позиція в рядку (перша, друга тощо) має номер. Це число називається індексом або іноді нижнім індексом.
- Індекси нумеруються від 0.
- Використовуйте індекс позиції у квадратних дужках, щоб отримати символ з тієї позиції у рядку.
![Рядок кода Python, print(atom_name[0]), демонструє, що використання нульового індексу виведе лише початкову літеру, у цьому випадку ‘h’ для ‘helium’.](fig/2_indexing.svg)
ВИВІД
hВикористовуйте зріз, щоб отримати підрядок.
- Частина рядка називається підрядок. Він може складатися навіть тільки з одного символу.
- Список складається з елементів. У випадку, коли рядок розглядається як список, його елементами є окремі символи.
- Зріз - це частина рядка (в загальному випадку, частина будь-якого обʼєкту, схожого на колекцію).
- Ми беремо зріз із позначенням
[start:stop], деstart— ціле число, що є індексом першого потрібного нам елементу, аstop- ціле число, що є індексом елементу відразу після останнього потрібного нам елементу. - Проміжок між
stopandstart- це довжина зрізу. - Визначення зрізу не змінює вміст вихідного рядка. Натомість, визначений зріз повертає копію початкового рядка.
ВИВІД
sodВикористовуйте вбудовану функцію len, щоб знайти
довжину рядка.
ВИВІД
6- Вкладені функції обчислюються зсередини назовні, як у математиці: вирази, що знаходяться всередині дужок, обчислюються першими.
Python чутливий до регістру.
- Python вважає, що букви верхнього та нижнього регістру
відрізняються, отже
Nameіname- різні змінні. - Існують домовленості про використання великих літер на початку імен змінних, тому ми будемо використовувати малі літери.
Використовуйте змістовні назви змінних.
- Ви можете використовувати будь-які комбінації символів для імен змінних, поки вони задовольняють вищевказані правила (букви, цифри та знак підкреслення).
- Використовуйте змістовні назви змінних, щоб допомогти іншим зрозуміти, що робить програма.
- Найважливіша “інша людина” — це ви в майбутньому.
ВИВІД
# Оператор # Значення x # Значення y # Значення swap #
x = 1.0 # 1.0 # не визначено # не визначено #
y = 3.0 # 1.0 # 3.0 # не визначено #
swap = x # 1.0 # 3.0 # 1.0 #
x = y # 3.0 # 3.0 # 1.0 #
y = swap # 3.0 # 1.0 # 1.0 #Ці три рядки обмінюються значеннями в x і y
використовуючи змінну swap для тимчасового зберігання. Це
досить поширена ідіома програмування.
Завдання
Якщо ви присвоїли a = 123, що станеться, якщо ви
спробуєте отримати другу цифру a через
a[1]?
Числа не є рядками або послідовностями, і спроба виконати операцію
індексу над числом у Python призведе до помилки. У наступному епізоді про типи даних і
перетворення типів ми дізнаємось більше про типи і як конвертувати
один тип в інший. Якщо вам потрібна N-та цифра числа, перетворіть його
на рядок за допомогою вбудованої функції str, а потім
виконайте операцію індексації у цьому рядку.
ПОМИЛКА
TypeError: 'int' object is not subscriptableВИВІД
2Вибір імені
Яке ім’я для змінної є кращим: m, min або
minutes? Чому? Підказка: подумайте, який код ви б хотіли
успадкувати від того, хто залишає лабораторію:
ts = m * 60 + stot_sec = min * 60 + sectotal_seconds = minutes * 60 + seconds
minutes краще, оскільки min можна помилково
прийняти за “мінімум” (що насправді є вбудованою функцією в Python, яку
ми розглянемо пізніше).
ВИВІД
atom_name[1:3] is: arРізноманітні види зрізів
Є наступний рядок:
Що виводять ці вирази?
species_name[2:8]-
species_name[11:](без значення після двокрапки) -
species_name[:4](без значення до двокрапки) -
species_name[:](тільки двокрапка) species_name[11:-3]species_name[-5:-3]- Що станеться, якщо ми оберемо значення
stop, яке виходить за рамки діапазону? (тобто спробуйте виконатиspecies_name[0:20]абоspecies_name[:103])
species_name[2:8]повертає підрядок'acia b'species_name[11:]повертає підрядок'folia', з позиції 11 до кінця рядкуspecies_name[:4]повертає підрядокAcac', з початку рядку до позиції 4, не включаючи цю позиціюspecies_name[:]повертає весь рядок ‘Acacia buxifolia’`species_name[11:-3]повертає підрядок'fo', з 11 позиції до третьої позиції з кінця рядку, не включаючи їїspecies_name[-5:-3]також повертає підрядок'fo', з п’ятої позиції з кінця до третьої позиції з кінця, не включаючи їїЯкщо частина фрагмента виходить за межі діапазону, операція не повертає помилку.
species_name[0:20]дає той самий результат, що іspecies_name[0:], таspecies_name[:103]дає такий самий результат, якspecies_name[:]
- Використовуйте змінні для зберігання значень.
- Використовуйте
printдля виводу значень. - Змінні зберігаються між комірками.
- Змінні мають бути створені перед їх використанням.
- Змінні можна використовувати для обчислень.
- Використовуйте індекс, щоб отримати один символ із рядка.
- Використовуйте зріз, щоб отримати підрядок.
- Використовуйте вбудовану функцію
len, щоб знайти довжину рядка. - У Python важливо, який регістр використовується.
- Використовуйте змістовні назви змінних.
Content from Типи даних та їх перетворення
Останнє оновлення 2026-06-18 | Редагувати цю сторінку
Огляд
Питання
- Які види даних зберігають програми?
- Як я можу перетворити один тип в інший?
Цілі
- Визначення ключових відмінностей між цілими числами та числами з плаваючою комою.
- З’ясувати ключові відмінності між числами та символьними рядками.
- Використання вбудованих функцій для перетворення цілих чисел, чисел з плаваючою комою та рядків.
Кожне значення має тип.
- Кожне значення, яке використовує програма, має певний тип.
- Ціле число (
int): зображує додатні або від’ємні цілі числа, наприклад 3 або -512. - Число з плаваючою комою (
float): зображує дійсні числа, наприклад 3.14159 або -2.5. - Рядки символів (зазвичай просто “рядки”,
str): представляють текст.- Укладені в одинарні або подвійні лапки (тип лапок має збігатися).
- Під час відображення рядку лапки не друкуються.
Вбудована функція type повертає тип значення.
- Використовуйте вбудовану функцію
type, щоб з’ясувати, який тип має значення. - Це також працює зі змінними.
- Але запамʼятайте: значення має свій тип, а змінна тільки вказує на деяке значення.
ВИВІД
<class 'int'>ВИВІД
<class 'str'>Тип визначає, які операції (або методи) можна виконувати над даним значенням.
- Тип значення визначає, що може робити з ним програма.
ВИВІД
2ПОМИЛКА
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-2-67f5626a1e07> in <module>()
----> 1 print('hello' - 'h')
TypeError: unsupported operand type(s) for -: 'str' and 'str'Ви можете використовувати оператори “+” та “*” для дій над рядками.
- “Додавання” рядків об’єднує їх.
ВИВІД
Ahmed Walsh- Якщо рядок помножити на ціле число N, то це створить новий
рядок, який буде містити вихідний рядок, повторений N разів.
- Оскільки множення - це повторюване додавання.
ВИВІД
==========Рядки мають довжину (але числа її не мають).
- Вбудована функція
lenповертає кількість символів у рядку.
ВИВІД
11- Але числа не мають довжини (навіть нульової).
ПОМИЛКА
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-3-f769e8e8097d> in <module>()
----> 1 print(len(52))
TypeError: object of type 'int' has no len()Необхідно перетворювати числа в рядки або навпаки під час виконання певних операцій.
- Додавання чисел та рядків неможливе.
ПОМИЛКА
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-4-fe4f54a023c6> in <module>()
----> 1 print(1 + '2')
TypeError: unsupported operand type(s) for +: 'int' and 'str'- Таке додавання не дозволено, тому що воно не визначене: чи має
1 + '2'повертати3чи'12'? - Перетворення типу виконується за допомогою функції, яка має те ж саме імʼя, що і потрібний тип.
ВИВІД
3
12З цілими та дійсними числами можна оперувати одночасно.
- Цілі та дійсні числа можна використовувати разом для арифметичних
дій.
- Python 3 автоматично перетворить цілі числа у дійсні, якщо це потрібно.
ВИВІД
half is 0.5
three squared is 9.0Змінні можуть змінити своє значення тільки через присвоєння.
- Якщо в електронних таблицях ми зробимо одну комірку залежною від іншої та оновимо останню, перша оновиться автоматично.
- Це не трапляється у мовах програмування.
PYTHON
variable_one = 1
variable_two = 5 * variable_one
variable_one = 2
print('first is', variable_one, 'and second is', variable_two)ВИВІД
first is 2 and second is 5- Комп’ютер зчитує значення
variable_oneпід час множення, створює нове значення та призначає цьому значенню ім’яvariable_two. - Після того, як значення
variable_twoвстановлено, воно не залежить від значенняvariable_one, отже його значення не змінюється автоматично, колиvariable_oneзмінюється.
Дроби
Який тип має значення 3.4? Як це можна встановити?
Автоматичне перетворення типів
Який тип має вираз 3.25 + 4?
Вибір типу
Який тип значення (ціле число, число з плаваючою комою або рядок символів) ви б використовували для представлення кожного з наступних значень? Спробуйте знайти більш ніж одну гарну відповідь для кожної проблеми. Наприклад у завданні # 1, коли було б доцільніше використовувати змінну з плаваючою комою замість цілого числа для підрахунку днів?
- Кількість днів, які пройшли з початку року.
- Час, що пройшов від початку року до сьогоднішнього дня.
- Серійний номер лабораторного обладнання.
- Вік лабораторного зразка
- Поточне населення міста.
- Середня чисельність населення міста протягом певного часу.
Відповіді на запитання:
Ціле, оскільки число днів належить діапазону від 1 до 365.
Дійсне число, оскільки потрібно використовувати частини дня.
Символьний рядок, якщо серійний номер містить літери та цифри, або ціле число, якщо серійний номер складається лише з цифр.
Це залежить від багатьох факторів! Як вимірюється вік зразка? Кількість днів з моменту, коли його було створено (ціле число)? Дата і час (рядок)?
Виберіть дійсне число, щоб представити приблизну кількість населення за допомогою округлення (наприклад, до мільйонів), або ціле число, щоб представити точну кількість населення.
Дійсне число, оскільки результат усереднення, швидше за все, буде мати дробну частину.
Типи операцій ділення
У Python 3 оператор // виконує ціле ділення (повертає
цілу частину результату), оператор / виконує ділення з
плаваючою комою, та оператор ‘%’ (або модуль) повертає залишок
від цілого ділення:
ВИВІД
5 // 3: 1
5 / 3: 1.6666666666666667
5 % 3: 2Припустимо, що num_subjects - це кількість суб’єктів,
які беруть участь у дослідженні, а num_per_survey —
кількість, яка може взяти участь в одному опитуванні. Напишіть вираз,
який обчислює кількість необхідних опитувань для охоплення кожного хоча
б один раз.
Потрібно визначити мінімальну кількість опитувань для охоплення
кожного суб’єкта хоча б один раз, тобто округлене значення
num_subjects/num_per_survey. Це еквівалентно виконанню
дійсного ділення за допомогою оператору // і додаванню 1 до
результату. Перед діленням нам потрібно відняти 1 від кількості
num_subjects, щоб працювати з випадком, коли
num_subjects порівну ділиться на
num_per_survey.
PYTHON
num_subjects = 600
num_per_survey = 42
num_surveys = (num_subjects - 1) // num_per_survey + 1
print(num_subjects, 'subjects,', num_per_survey, 'per survey:', num_surveys)ВИВІД
600 subjects, 42 per survey: 15Перетворення рядків у числа
Якщо потрібно, функція float() перетворить рядок у
дійсне число, а функція int() перетворить дійсне число в
ціле:
ВИВІД
string to float: 3.4
float to int: 3Якщо перетворення не має сенсу, то генерується повідомлення про помилку.
ПОМИЛКА
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-5-df3b790bf0a2> in <module>
----> 1 print("string to float:", float("Hello world!"))
ValueError: could not convert string to float: 'Hello world!'Беручи це до уваги, чого чекати від наступної програми?
Що вона робить насправді?
Як це пояснити?
Що ви очікуєте від цієї програми? Чому б не очікувати, що у Python 3
команда int перетворить рядок “3.4” на 3.4 та виконає
додаткове перетворення у ціле число 3. Зрештою, Python 3 вміє робити
багато іншої “магії” - хіба це не частина його привабливості?
ВИВІД
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-2-ec6729dfccdc> in <module>
----> 1 int("3.4")
ValueError: invalid literal for int() with base 10: '3.4'Однак Python 3 видає помилку. Чому? Можливо, щоб бути послідовним. Якщо вам потрібно, щоб Python виконав два послідовних перетворення типів, ви повинні чітко вказати кожне перетворення у своєму коді.
ВИВІД
3Арифметичні дії з різними типами
Правильні відповіді: 1 та 4
Комплексні числа
Python підтримує комплексні числа, які записуються як
1.0 + 2.0j. Якщо val є комплексним числом, то
до його дійсної та уявної частин можна отримати доступ за допомогою так
званої крапкової нотації через val.real та
val.imag.
ВИВІД
6.0
2.0- Чому, на вашу думку, Python використовує
jзамістьiдля уявної частини? - Який результат слід очікувати від виразу
1 + 2j + 3? - Що ви очікуєте від
4j? А що від4 jабо4 + j?
Стандартні математичні позначення зазвичай використовують
iдля позначення комплексного числа. Однак різні джерела свідчать про те, що це було раннє позначення, яке використовувалось в електротехніці, та зараз було б дуже складно з технічної точки зору його змінити. Stack Overflow містить додаткові пояснення та обговорення.(4+2j)4jабоSyntax Error: invalid syntax. В останньому випадкуjвважається змінною і значення виразу залежить від того, чи єjвизначеним.
- Кожне значення має тип.
- Вбудована функція
typeповертає тип значення. - Типи контролюють, які операції можна виконувати над значеннями.
- Рядки можна додавати і помножувати.
- Рядки мають довжину (але числа її не мають).
- Необхідно перетворювати числа в рядки або навпаки під час виконання певних операцій.
- Цілі та дійсні числа можна використовувати разом.
- Змінні можуть набути своє значення тільки через присвоювання.
Content from Вбудовані функції та довідка
Останнє оновлення 2026-06-18 | Редагувати цю сторінку
Огляд
Питання
- Як я можу використовувати вбудовані функції?
- Як я можу дізнатися, для чого вони призначені?
- Які помилки можуть виникнути в програмах?
Цілі
- Пояснення призначення функцій.
- Коректний виклик вбудованих функцій Python.
- Правильне використання вкладених вбудованих функцій.
- Використання довідки для відображення документації про вбудовані функції.
- Правильний опис ситуацій, в яких виникають помилки SyntaxError і NameError.
Використовуйте коментарі при створенні документації програм.
Функції можуть приймати нуль або більше аргументів.
- Ми вже знайомі з деякими функціями — тепер розглянемо їх докладніше.
- Аргумент - це значення, яке передається у функцію.
-
lenпотребує тільки один аргумент. -
int,strтаfloatстворюють нові значення з наявних. -
printможе приймати нуль або більше аргументів. -
printбез аргументів повертає порожній рядок.- Потрібно завжди використовувати дужки, навіть якщо вони порожні, щоб Python знав, що викликається функція.
ВИВІД
before
afterКожна функція щось повертає.
- Кожен виклик функції дає певний результат.
- Якщо функція не має корисного результату для повернення, то вона
зазвичай повертає спеціальне значення
None.None- це об’єкт Python, який застосовується у будь-якому випадку, коли немає значення.
ВИВІД
example
result of print is NoneПоширені вбудовані функції max, min та
round.
- Використовуйте
max, щоб знайти найбільше з одного або декількох значень. - Використовуйте
min, щоб знайти найменше значення. - Обидві функції працюють як з рядками символів, так і з числами.
- Літери порівнюються у лексикографічному порядку, при цьому цифри “менші” ніж великі літери, а великі літери “менші” ніж малі.
ВИВІД
3
0Функції працюють лише з певними аргументами (або комбінаціями аргументів).
-
maxтаminмають приймати принаймні один аргумент.- “Найбільше значення з порожньої множини” - запит, який не має сенсу.
- Крім того, аргументи цих функцій мають бути порівнюваними.
ПОМИЛКА
TypeError Traceback (most recent call last)
<ipython-input-52-3f049acf3762> in <module>
----> 1 print(max(1, 'a'))
TypeError: '>' not supported between instances of 'str' and 'int'Функції можуть мати значення за замовчуванням для певних аргументів.
-
roundокруглює дійсне число. - За замовчуванням округлення відбувається до нуля знаків після точки.
ВИВІД
4- Ми можемо вказати потрібну кількість десяткових знаків після крапки.
ВИВІД
3.7Функції, приєднані до об’єктів, називаються методами
- Функції можуть набувати іншої форми, яка буде типовою для епізодів, пов’язаних з бібліотекою pandas.
- Методи мають такі дужки як функції, але з’являються в описі оператора після імені змінної.
- Деякі методи використовуються для внутрішніх операцій Python і відзначаються подвійними підкресленнями.
PYTHON
my_string = 'Hello world!' # створення об'єкта - рядка
print(len(my_string)) # функція len приймає рядок як аргумент і повертає довжину рядка
print(my_string.swapcase()) # виклик методу swapcase для об’єкта my_string
print(my_string.__len__()) # виклик внутрішнього методу __len__ для об’єкта my_string, який використовується функцією len(my_string)ВИВІД
12
hELLO WORLD!
12- Ви навіть можете побачити, як вони зв’язані. Вони працюють зліва направо.
PYTHON
print(my_string.isupper()) # Функція перевіряє, чи всі літери заглавні
print(my_string.upper()) # Функція перетворює всі літери на заглавні
print(my_string.upper().isupper()) # Тепер всі літери заглавніВИВІД
False
HELLO WORLD
TrueВикористовуйте вбудовану функцію help, щоб отримати
довідку щодо функції.
- Кожна вбудована функція має онлайн-документацію.
ВИВІД
Файл допомоги щодо вбудованої функції round зі стандартної бібліотеки Python:
round(number, ndigits=None)
Round a number to a given precision in decimal digits.
The return value is an integer if ndigits is omitted or None. Otherwise
the return value has the same type as the number. ndigits may be negative.Два шляхи отримання допомоги у Jupyter Notebook.
- Варіант 1: Помістіть курсор біля того місця, де функція викликається
в комірці (тобто біля назви функції або її параметрів),
- Утримуйте Shiftта натисніть Tab.
- Зробіть це кілька разів для розширення інформації, що повертається.
- Варіант 2: Введіть ім’я функції в комірці зі знаком питання після нього. Потім запустіть комірку.
Python повідомляє про синтаксичну помилку, коли він не може зрозуміти вихідний код програми.
- Він навіть не намагатиметься запустити програму, якщо її неможливо коректно прочитати.
ПОМИЛКА
File "<ipython-input-56-f42768451d55>", line 2
name = 'Feng
^
SyntaxError: EOL while scanning string literalПОМИЛКА
File "<ipython-input-57-ccc3df3cf902>", line 2
age = = 52
^
SyntaxError: invalid syntax- Подивіться уважніше на повідомлення про помилку:
ПОМИЛКА
File "<ipython-input-6-d1cc229bf815>", line 1
print ("hello world"
^
SyntaxError: unexpected EOF while parsing- Повідомлення вказує на проблему в першому рядку введеної програми
(“line 1”).
- У цьому випадку “ipython-input” у назві файлу повідомляє нам, що ми працюємо з IPython, тобто з інтерпретатором Python, який застосовується в Jupyter Notebook.
- Фрагмент
-6-в назві файлу вказує на те, що помилка сталася в комірці 6. - Далі йде проблемний рядок коду, на що вказує символ
^.
Python повідомляє про помилку виконання, коли щось йде не так під час виконання програми.
ПОМИЛКА
NameError Traceback (most recent call last)
<ipython-input-59-1214fb6c55fc> in <module>
1 age = 53
----> 2 remaining = 100 - aege # mis-spelled 'age'
NameError: name 'aege' is not defined- Аналіз вихідного кода дозволяє виправити синтаксичні помилки, а на етапі компілювання можна виправити помилки виконання.
Порядок виконання операцій
Порядок виконання операцій:
1.1 * radiance = 1.11.1 - 0.5 = 0.6min(radiance, 0.6) = 0.62.0 + 0.6 = 2.6max(2.1, 2.6) = 2.6На кінець,
radiance = 2.6
Знайдіть відмінності
- Подумайте, що виведе кожен з операторів
printу наведеній нижче програмі. - Функція
max(len(rich), poor)поверне відповідь або повідомлення про помилку? Якщо поверне відповідь, чи буде вона мати сенс?
ВИВІД
cВИВІД
tinВИВІД
4max(len(rich), poor) повертає TypeError. Помилка виникає
при виконанні max(4, 'tin') тому що, як ми обговорювали
раніше, порівнювати рядок і ціле число не можна.
ПОМИЛКА
TypeError Traceback (most recent call last)
<ipython-input-65-bc82ad05177a> in <module>
----> 1 max(len(rich), poor)
TypeError: '>' not supported between instances of 'str' and 'int'Чому ні?
Чому саме max і min не повертають
None, коли вони викликаються без аргументів?
max and min повертають TypeErrors у цьому
випадку, тому що не було вказано правильну кількість параметрів. Якби
компілятор просто повернув None, помилку було б набагато
важче відстежити, тому що це значення було б збережено в змінній і
використано пізніше в програмі.
Останній символ рядка
Якщо Python починає рахувати з нуля, та len повертає
кількість символів у рядку, то який індекс отримає останній символ у
рядку name? (Примітка: ми побачимо простіший спосіб зробити
це в подальшому епізоді)
name[len(name) - 1]
Вивчайте документацію Python!
Офіційна документація Python вочевидь є найповнішим джерелом інформації про мову. Вона доступна різними мовами та містить багато корисних ресурсів. Сторінка вбудованих функцій містить каталог усіх таких функцій, включаючи ті, про які ми вже говорили на цьому уроці. Деякі з них більш досконалі та на цей час зайві, але інші - дуже прості та корисні.
- Використовуйте коментарі при створенні документації програм.
- Функції можуть сприймати нуль або більше аргументів.
- Поширені вбудовані функції
max,minтаround. - Функції можуть працювати лише з певними аргументами (комбінаціями аргументів).
- Функції можуть мати значення за замовчуванням для певних аргументів.
- Використовуйте вбудовану функцію
help, щоб отримати довідку щодо функції. - Є два шляхи отримання допомоги у Jupyter Notebook.
- Кожна функція щось повертає.
- Python повідомляє про синтаксичну помилку, коли він не може зрозуміти вихідний код програми.
- Python повідомляє про помилку виконання (runtime error), коли щось йде не так під час виконання програми.
- Якщо перечитаєте вихідний код, можна виправити синтаксичні помилки, а якщо відстежите дії інтерпретатора - помилки виконання.
Content from Ранкова кава
Останнє оновлення 2026-06-18 | Редагувати цю сторінку
Вправа для рефлексії
За кавою подумайте і обговоріть наступне:
- Якими є різні типи помилок в Python?
- Чи завжди код давав очікувані результати? Якщо ні, то чому?
- Чи можна щось зробити, щоб запобігти помилкам під час написання коду?
Content from Бібліотеки
Останнє оновлення 2026-06-18 | Редагувати цю сторінку
Огляд
Питання
- Як використовувати програмне забезпечення, написане іншими людьми?
- Як дізнатися, які саме функції виконує це програмне забезпечення?
Цілі
- Переваги створення та використання бібліотек програмного забезпечення.
- Імпорт та використання стандартних бібліотек Python у власних програмах.
- Пошук документації про стандартні бібліотеки в інтерактивному режимі (в інтерпретаторі) або онлайн.
Більша частина потужності мови програмування полягає в її бібліотеках.
-
Бібліотека - це колекція файлів (так званих
модулів), що містить функції для використання іншими
програмами.
- Може також визначати значення даних (наприклад, числові константи) та інші речі.
- Передбачається, що зміст бібліотеки певним чином взаємопов’язаний, але немає засобів це проконтролювати.
- Стандартна бібліотека Python — це великий набір модулів, що входить до складу базової інсталяції Python.
- Багато додаткових бібліотек доступні в PyPI (Python Package Index - репозиторій програм для Python).
- Пізніше ми побачимо, як писати нові бібліотеки.
Бібліотеки та модулі
Бібліотека — це набір модулів, але ці терміни часто вважаються взаємозамінними, особливо тому, що багато бібліотек складаються лише з одного модуля, тому не хвилюйтеся, якщо ви їх плутаєте.
Щоб використати бібліотечний модуль, його спочатку потрібно імпортувати.
- Для завантаження бібліотечного модуля в пам’ять програми
використовуйте
import. - Потім посилайтеся на функції модуля за допомогою
module_name.function_name.- У Python синтаксис
a.bозначає щоaміститьb, або іншими словами,bє частиноюa, абоbналежить доa.
- У Python синтаксис
- Використовуючи
math, один із модулів стандартної бібліотеки, маємо:
ВИВІД
pi is 3.141592653589793
cos(pi) is -1.0- На кожен елемент модуля потрібно посилатися разом з його назвою.
-
math.cos(pi)не спрацює: посилання наpiжодним чином не “успадковує” посилання наmathпри виклику функціїcos().
-
Використовуйте help, щоб дізнатися про вміст
бібліотечного модуля.
- Працює так само, як довідка для функції.
ВИВІД
Help on module math:
NAME
math
MODULE REFERENCE
http://docs.python.org/3/library/math
The following documentation is automatically generated from the Python
source files. It may be incomplete, incorrect or include features that
are considered implementation detail and may vary between Python
implementations. When in doubt, consult the module reference at the
location listed above.
DESCRIPTION
This module is always available. It provides access to the
mathematical functions defined by the C standard.
FUNCTIONS
acos(x, /)
Return the arc cosine (measured in radians) of x.
⋮ ⋮ ⋮Щоб скоротити програми, імпортуйте лише певні елементи з бібліотечного модуля.
- Використовуйте
from ... import ..., щоб завантажити лише певні елементи з бібліотечного модуля. - Потім звертайтеся до них безпосередньо без назви бібліотеки як префікса.
ВИВІД
cos(pi) is -1.0Створіть псевдонім для бібліотечного модуля під час його імпорту для скорочення програм.
- Використовуйте
import ... ... as ..., щоб надати бібліотеці короткий псевдонім під час її імпорту. - Потім звертайтеся до елементів у бібліотеці, використовуючи цю скорочену назву.
ВИВІД
cos(pi) is -1.0- Зазвичай цей метод використовується для бібліотек, які дуже поширені
або мають довгі імена.
- Наприклад, бібліотека для побудови графіків
matplotlibчасто має псевдонімmpl.
- Наприклад, бібліотека для побудови графіків
- Але цей спосіб ускладнює програми, оскільки читачі мають вивчити псевдоніми вашої програми.
Знайомство з модулем math
- За допомогою якої функції з модуля
mathможна обчислити квадратний корінь без використанняsqrt? - Оскільки бібліотека містить цю функцію, чому існує
sqrt?
Використовуючи
help(math)ми бачимо, що у нас єpow(x,y)на додаток доsqrt(x), отже ми можемо застосуватиpow(x, 0.5)для визначення квадратного кореня.Функція
sqrt(x), ймовірно, легша для читання в вихідному коді, ніжpow(x, 0.5). Читабельність є основою хорошого стилю програмування, отже має сенс надати спеціальну функцію для цього конкретного поширеного випадку.
Крім того, дизайн бібліотеки math у Python бере свій
початок у стандарті мови C, яка включає як sqrt(x), так і
pow(x,y), тож трохи історії програмування відображається в
назвах функцій Python.
Пошук правильного модуля
Припустимо, ви хочете вибрати випадковий символ з рядка:
- Який модуль зі стандартної бібліотеки може допомогти?
- Яку функцію ви б вибрали з цього модуля? Чи є альтернативи?
- Спробуйте написати програму, яка використовує цю функцію.
Здається, модуль random може допомогти.
Рядок містить 11 символів, кожен з яких має позиційний індекс від 0
до 10. Ви можете використовувати функції random.randrange
або random.randint,
щоб отримати випадкове число від 0 до 10, а потім вибрати символ з
bases в цій позиції:
або більш компактно:
Можливо, ви знайшли ще функцію random.sample?
Ця функція дозволяє використовувати трохи менше коду, але може бути
трохи складнішою для розуміння при читанні:
Зверніть увагу, що ця функція повертає список (list) значень. Ми дізнаємося про списки у епізоді 11.
Найпростіше і найкоротше рішення - це функція random.choice,
яка виконує саме те, чого ми хочемо:
Головоломка (задача Парсона). Приклад програмування
Упорядкуйте наступні оператори таким чином, щоб друкувалась випадкова основа ДНК та її індекс в рядку. Не всі оператори можуть бути потрібні. За необхідності додавайте проміжні змінні.
Коли доступна допомога?
Ваш колега виконав запит help(math). Python повернув
помилку:
ПОМИЛКА
NameError: name 'math' is not definedЩо забув зробити ваш колега?
Імпортувати модуль math (import math)
можна записати як
Оскільки ви щойно написали код і знайомі з ним, вам справді легше читати першу версію. Але при спробі прочитати величезну купу коду, написаного кимось іншим, або коли повертаєтесь до свого власного величезного фрагмента коду через кілька місяців, нескорочені імена часто легші, за винятком випадку, де є чіткі умовні позначення скорочень.
Існує багато способів імпорту бібліотек!
Зіставте наступні команди друку з відповідними викликами бібліотеки.
Команди друку:
print("sin(pi/2) =", sin(pi/2))print("sin(pi/2) =", m.sin(m.pi/2))print("sin(pi/2) =", math.sin(math.pi/2))
Виклик бібліотеки:
from math import sin, piimport mathimport math as mfrom math import *
- Виклики бібліотеки 1 та 4. Для прямого посилання на
sinтаpiбез назви бібліотеки як префікса, вам потрібно використовувати операторfrom ... import .... Виклик бібліотеки 1 явним чином імпортує дві функціїsinтаpi, тоді як виклик бібліотеки 4 імпортує всі функції з модуляmath. - Виклик бібліотеки 3. Тут
sinтаpiпосилаються на скорочену назву бібліотекиmзамістьmath. Це стає можливим завдяки командіimport ... as ...яка створює псевдонім дляmathв формі короткого іменіm. - Виклик бібліотеки 2. Тут
sinтаpiпосилаються на бібліотекуmathза її стандартним імʼям, тому буде достатньо звичайного викликуimport ....
Примітка: хоча виклик бібліотеки 4 працює, імпорт
всіх імен модуля за допомогою шаблона * не рекомендується, тому що в такому
разі невідомо, які імена з модуля використовуються в коді. Загалом,
краще робити імпорт якомога точнішим та імпортувати лише те, що
використовує ваш код. У виклику бібліотеки 1 оператор
import явно повідомляє нам що функція sin
імпортується з модуля math, але виклик бібліотеки 4 не
передає цю інформацію.
Скоріше за все, цю версію легше читати, оскільки вона менш насичена.
Основною причиною не використовувати цю форму імпорту є уникнення збігу
імен. Наприклад, ви б не імпортували degrees таким чином,
якби також хотіли використовувати назву degrees для власної
змінної або функції. Або якщо вам необхідно також імпортувати функцію з
назвою degrees з іншої бібліотеки.
ВИВІД
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-1-d72e1d780bab> in <module>
1 from math import log
----> 2 log(0)
ValueError: math domain errorЛогарифм
xвизначено лише дляx > 0, тому 0 знаходиться за межами області визначення функції.Ви отримуєте повідомлення про помилку типу
ValueError, яке вказує на те, що функція отримала неприпустиме значення аргументу. Додаткове повідомлення “math domain error” пояснює, в чому полягає проблема.
- Більша частина потужності мови програмування полягає в її бібліотеках.
- Щоб використати бібліотечний модуль, його спочатку потрібно імпортувати.
- Використовуйте
help, щоб дізнатися про вміст бібліотечного модуля. - Імпортуйте певні елементи з бібліотечного модуля, щоб скоротити програми.
- Створюйте псевдонім для бібліотечного модуля під час його імпорту для скорочення програм.
Content from Зчитування табличних даних у датафрейми
Останнє оновлення 2026-06-18 | Редагувати цю сторінку
Огляд
Питання
- Як я можу завантажити табличні дані у датафрейми Pandas?
Цілі
- Імпорт бібліотеки Pandas.
- Використання Pandas для завантаження набору даних у CSV форматі.
- Базова інформація про датафрейми бібліотеки Pandas.
Використовуйте бібліотеку Pandas для статистичного аналізу табличних даних.
- Pandas - це бібліотека Python, яка широко використовується для статистичного аналізу, зокрема при роботі з табличними даними.
- Ця бібліотека запозичує багато функцій з датафреймів мови R.
- Датафрейм — це двовимірна таблиця з іменованими стовпцями, які потенційно містять різні типи даних.
- Завантажте цю бібліотеку за допомогою
import pandas as pd. Псевдонімpdзазвичай використовується для посилання на бібліотеку Pandas у коді. - Файл даних зі значеннями, розділеними комами (Comma Separate Values
- CSV), читається за допомогою
pd.read_csv.- Аргумент — це ім’я файлу, який потрібно прочитати.
- Ця команда повертає датафрейм, який ви можете присвоїти змінній
PYTHON
import pandas as pd
data_oceania = pd.read_csv('data/gapminder_gdp_oceania.csv')
print(data_oceania)ВИВІД
country gdpPercap_1952 gdpPercap_1957 gdpPercap_1962 \
0 Australia 10039.59564 10949.64959 12217.22686
1 New Zealand 10556.57566 12247.39532 13175.67800
gdpPercap_1967 gdpPercap_1972 gdpPercap_1977 gdpPercap_1982 \
0 14526.12465 16788.62948 18334.19751 19477.00928
1 14463.91893 16046.03728 16233.71770 17632.41040
gdpPercap_1987 gdpPercap_1992 gdpPercap_1997 gdpPercap_2002 \
0 21888.88903 23424.76683 26997.93657 30687.75473
1 19007.19129 18363.32494 21050.41377 23189.80135
gdpPercap_2007
0 34435.36744
1 25185.00911- Стовпці у датафреймі – це спостережувані змінні, а рядки – це спостереження.
- Pandas використовує зворотну скісну риску
\для позначення перенесених рядків, коли вивід занадто широкий для розміщення на екрані. - Використання змістовних імен для датафреймів допомагає нам розрізняти кілька датафреймів, запобігаючи випадковому перезапису або помилковому читанню.
Файл не знайдено
Наші уроки зберігають свої файли даних у підкаталозі
data, тому шлях до файлу є таким:
data/gapminder_gdp_oceania.csv. Якщо ви забули
додатиdata/, або якщо ваша копія файлу знаходиться в іншому
місці, ви отримаєте runtime error, який
закінчується таким рядком:
ПОМИЛКА
FileNotFoundError: [Errno 2] No such file or directory: 'data/gapminder_gdp_oceania.csv'Використовуйте index_col, щоб вказати стовпець,
значення якого мають використовуватися як заголовки рядків.
- Заголовки рядків є числами (0 і 1 у цьому випадку).
- Але насправді краще індексувати за назвами країн.
- Для цього передайте назву стовпця в
read_csvяк параметрindex_col. - Назва датафрейму
data_oceania_countryговорить нам про те, з якою географічною зоною пов’язані дані (oceania) та про те, як вони індексуються (country).
PYTHON
data_oceania_country = pd.read_csv('data/gapminder_gdp_oceania.csv', index_col='country')
print(data_oceania_country)ВИВІД
gdpPercap_1952 gdpPercap_1957 gdpPercap_1962 gdpPercap_1967 \
country
Australia 10039.59564 10949.64959 12217.22686 14526.12465
New Zealand 10556.57566 12247.39532 13175.67800 14463.91893
gdpPercap_1972 gdpPercap_1977 gdpPercap_1982 gdpPercap_1987 \
country
Australia 16788.62948 18334.19751 19477.00928 21888.88903
New Zealand 16046.03728 16233.71770 17632.41040 19007.19129
gdpPercap_1992 gdpPercap_1997 gdpPercap_2002 gdpPercap_2007
country
Australia 23424.76683 26997.93657 30687.75473 34435.36744
New Zealand 18363.32494 21050.41377 23189.80135 25185.00911Використовуйте DataFrame.info(), щоб дізнатися більше
про датафрейми.
ВИВІД
<class 'pandas.core.frame.DataFrame'>
Index: 2 entries, Australia to New Zealand
Data columns (total 12 columns):
gdpPercap_1952 2 non-null float64
gdpPercap_1957 2 non-null float64
gdpPercap_1962 2 non-null float64
gdpPercap_1967 2 non-null float64
gdpPercap_1972 2 non-null float64
gdpPercap_1977 2 non-null float64
gdpPercap_1982 2 non-null float64
gdpPercap_1987 2 non-null float64
gdpPercap_1992 2 non-null float64
gdpPercap_1997 2 non-null float64
gdpPercap_2002 2 non-null float64
gdpPercap_2007 2 non-null float64
dtypes: float64(12)
memory usage: 208.0+ bytes- Це
DataFrame - Містить два рядки з назвами
'Australia'та'New Zealand' - А також дванадцять стовпців, кожен з яких містить два 64-бітних
значення з плаваючою комою.
- Пізніше ми поговоримо про
nullзначення, які використовуються для представлення відсутніх спостережень.
- Пізніше ми поговоримо про
- Використовує 208 байтів пам’яті.
Змінна DataFrame.columns зберігає інформацію про
стовпці датафрейму.
- Зверніть увагу, що це дані, а не метод. (Відсутні дужки)
- Подібно до
math.pi. - Тому не використовуйте
(), тому що це - не функція.
- Подібно до
- Ця змінна називається атрибутом.
ВИВІД
Index(['gdpPercap_1952', 'gdpPercap_1957', 'gdpPercap_1962', 'gdpPercap_1967',
'gdpPercap_1972', 'gdpPercap_1977', 'gdpPercap_1982', 'gdpPercap_1987',
'gdpPercap_1992', 'gdpPercap_1997', 'gdpPercap_2002', 'gdpPercap_2007'],
dtype='object')Використовуйте DataFrame.T, щоб транспонувати
датафрейм.
- Іноді потрібно розглядати стовпці як рядки та навпаки.
- Транспонування (written
.T) не копіює дані, а лише змінює їх подання. - Подібно до
columns, це атрибут датафрейму.
ВИВІД
country Australia New Zealand
gdpPercap_1952 10039.59564 10556.57566
gdpPercap_1957 10949.64959 12247.39532
gdpPercap_1962 12217.22686 13175.67800
gdpPercap_1967 14526.12465 14463.91893
gdpPercap_1972 16788.62948 16046.03728
gdpPercap_1977 18334.19751 16233.71770
gdpPercap_1982 19477.00928 17632.41040
gdpPercap_1987 21888.88903 19007.19129
gdpPercap_1992 23424.76683 18363.32494
gdpPercap_1997 26997.93657 21050.41377
gdpPercap_2002 30687.75473 23189.80135
gdpPercap_2007 34435.36744 25185.00911Використовуйте DataFrame.describe, щоб отримати зведену
статистику даних.
DataFrame.describe() отримує зведену статистику лише для
стовпців, які містять числові дані. Якщо ви не використовуєте аргумент
include='all', усі інші стовпці ігноруються.
ВИВІД
gdpPercap_1952 gdpPercap_1957 gdpPercap_1962 gdpPercap_1967 \
count 2.000000 2.000000 2.000000 2.000000
mean 10298.085650 11598.522455 12696.452430 14495.021790
std 365.560078 917.644806 677.727301 43.986086
min 10039.595640 10949.649590 12217.226860 14463.918930
25% 10168.840645 11274.086022 12456.839645 14479.470360
50% 10298.085650 11598.522455 12696.452430 14495.021790
75% 10427.330655 11922.958888 12936.065215 14510.573220
max 10556.575660 12247.395320 13175.678000 14526.124650
gdpPercap_1972 gdpPercap_1977 gdpPercap_1982 gdpPercap_1987 \
count 2.00000 2.000000 2.000000 2.000000
mean 16417.33338 17283.957605 18554.709840 20448.040160
std 525.09198 1485.263517 1304.328377 2037.668013
min 16046.03728 16233.717700 17632.410400 19007.191290
25% 16231.68533 16758.837652 18093.560120 19727.615725
50% 16417.33338 17283.957605 18554.709840 20448.040160
75% 16602.98143 17809.077557 19015.859560 21168.464595
max 16788.62948 18334.197510 19477.009280 21888.889030
gdpPercap_1992 gdpPercap_1997 gdpPercap_2002 gdpPercap_2007
count 2.000000 2.000000 2.000000 2.000000
mean 20894.045885 24024.175170 26938.778040 29810.188275
std 3578.979883 4205.533703 5301.853680 6540.991104
min 18363.324940 21050.413770 23189.801350 25185.009110
25% 19628.685413 22537.294470 25064.289695 27497.598692
50% 20894.045885 24024.175170 26938.778040 29810.188275
75% 22159.406358 25511.055870 28813.266385 32122.777857
max 23424.766830 26997.936570 30687.754730 34435.367440- Це не додає багато нової інформації у випадку лише двох записів, але дуже корисно, коли їх тисячі.
Ще одна вправа на читання даних
Зчитайте дані з файлу gapminder_gdp_americas.csv (який
має бути в тому ж каталозі, що й gapminder_gdp_oceania.csv)
у змінну data_americas і відобразіть її зведену
статистику.
Щоб зчитати CSV-файл, ми використовуємо функцію
pd.read_csv і передаємо їй ім’я файлу
'data/gapminder_gdp_americas.csv' як аргумент. Також ми
передаємо назву стовпця 'country' у параметрі
index_col, щоб індексувати за країною. Зведену статистику
можна показати за допомогою методу
DataFrame.describe().
Перевірка даних
Після введення датафрейму data_americas попрацюйте з
довідкою help(data_americas.head) та
help(data_americas.tail), щоб дізнатися про призначення
команд DataFrame.head та DataFrame.tail.
- Виклик якого методу виведе перші три рядки цього датафрейму?
- Виклик якого методу виведе останні три стовпці цього датафрейму? (Підказка: вам може знадобитися змінити спосіб перегляду даних).
- Ми можемо побачити перші п’ять рядків датафрейму
data_americasза допомогоюdata_americas.head(), що дозволяє нам швидко переглянути його структуру. Ми можемо вказати кількість рядків, які ми хочемо бачити, визначивши параметрnу нашому викликуamericas.head(). Для перегляду перших трьох рядків виконайте:
ВИВІД
continent gdpPercap_1952 gdpPercap_1957 gdpPercap_1962 \
country
Argentina Americas 5911.315053 6856.856212 7133.166023
Bolivia Americas 2677.326347 2127.686326 2180.972546
Brazil Americas 2108.944355 2487.365989 3336.585802
gdpPercap_1967 gdpPercap_1972 gdpPercap_1977 gdpPercap_1982 \
country
Argentina 8052.953021 9443.038526 10079.026740 8997.897412
Bolivia 2586.886053 2980.331339 3548.097832 3156.510452
Brazil 3429.864357 4985.711467 6660.118654 7030.835878
gdpPercap_1987 gdpPercap_1992 gdpPercap_1997 gdpPercap_2002 \
country
Argentina 9139.671389 9308.418710 10967.281950 8797.640716
Bolivia 2753.691490 2961.699694 3326.143191 3413.262690
Brazil 7807.095818 6950.283021 7957.980824 8131.212843
gdpPercap_2007
country
Argentina 12779.379640
Bolivia 3822.137084
Brazil 9065.800825- Щоб перевірити останні три рядки
data_americas, ми можемо використати командуdata_americas.tail(n=3), яка аналогічна методуhead(), що застосовувався вище. Однак тут ми хочемо переглянути останні три стовпці, тому нам потрібно змінити подання інформації, а потім використати методtail(). Для цього ми маємо транспонувати цей датафрейм:
Тепер ми можемо переглянути останні три стовпці
data_americas за допомогою перегляду останніх трьох рядків
americas_flipped:
ВИВІД
country Argentina Bolivia Brazil Canada Chile Colombia \
gdpPercap_1997 10967.3 3326.14 7957.98 28954.9 10118.1 6117.36
gdpPercap_2002 8797.64 3413.26 8131.21 33329 10778.8 5755.26
gdpPercap_2007 12779.4 3822.14 9065.8 36319.2 13171.6 7006.58
country Costa Rica Cuba Dominican Republic Ecuador ... \
gdpPercap_1997 6677.05 5431.99 3614.1 7429.46 ...
gdpPercap_2002 7723.45 6340.65 4563.81 5773.04 ...
gdpPercap_2007 9645.06 8948.1 6025.37 6873.26 ...
country Mexico Nicaragua Panama Paraguay Peru Puerto Rico \
gdpPercap_1997 9767.3 2253.02 7113.69 4247.4 5838.35 16999.4
gdpPercap_2002 10742.4 2474.55 7356.03 3783.67 5909.02 18855.6
gdpPercap_2007 11977.6 2749.32 9809.19 4172.84 7408.91 19328.7
country Trinidad and Tobago United States Uruguay Venezuela
gdpPercap_1997 8792.57 35767.4 9230.24 10165.5
gdpPercap_2002 11460.6 39097.1 7727 8605.05
gdpPercap_2007 18008.5 42951.7 10611.5 11415.8Це показує потрібні нам дані, але якщо ми віддаємо перевагу перегляду трьох стовпців замість трьох рядків, ми можемо додатково транспонувати останній результат:
Примітка: того самого результату можна було досягти за допомогою однієї команди, об’єднавши команди в ‘ланцюжок’:
Читання файлів в інших каталогах
Дані вашого поточного проєкту зберігаються у файлі під назвою
microbes.csv, який знаходиться в каталозі
field_data. Ви виконуєте аналіз у блокноті під назвою
analysis.ipynb, який розміщено у сусідньому каталозі
thesis:
ВИВІД
your_home_directory
+-- field_data/
| +-- microbes.csv
+-- thesis/
+-- analysis.ipynbЯкі значення вам потрібно передати у функцію read_csv,
щоб прочитати microbes.csv з блокнота
analysis.ipynb?
Нам треба вказати шлях до потрібного файлу як аргумент функції
pd.read_csv. По-перше, потрібно ‘вийти’ з каталогу
thesis за допомогою ‘../’, а потім ‘зайти’ у каталог
field_data за допомогою ‘field_data/’. Після цього вказати
назву файлу microbes.csv. Кінцевий результат наступний:
Запис даних
Окрім функції read_csv для зчитування даних з файлу,
Pandas надає функцію to_csv для запису датафреймів у файли.
Використовуючи знання про читання з файлів, запишіть один з ваших
датафреймів у файл під назвою processed.csv. Ви можете
скористатися help, щоб отримати інформацію про застосування
to_csv.
Щоб записати датафрейм americas у файл
processed.csv, виконайте таку команду:
Щоб отримати довідку щодо read_csv або
to_csv, ви можете виконати, наприклад:
Зауважте, що команди help(to_csv) або
help(pd.to_csv) є помилковими! Це пов’язано з тим, що
to_csv є не глобальною функцією Pandas, а методом,
визначеним для датафреймів. Це означає, що ви можете викликати його лише
для будь-якого датафрейма, наприклад, data_americas.to_csv
або data_oceania.to_csv
- Використовуйте бібліотеку Pandas для обчислення базової статистики з табличних даних.
- Використовуйте
index_col, щоб призначити значення стовпця як заголовки рядків. - Використовуйте
DataFrame.info, щоб дізнатися більше про структуру датафрейму. - Змінна
DataFrame.columnsзберігає інформацію про стовпці датафрейму. - Використовуйте
DataFrame.T, щоб транспонувати датафрейм. - Використовуйте
DataFrame.describe, щоб отримати зведену статистику даних.
Content from Датафрейми Pandas
Останнє оновлення 2026-06-18 | Редагувати цю сторінку
Огляд
Питання
- Як я можу виконати статистичний аналіз табличних даних?
Цілі
- Вибір окремих значень з датафрейму Pandas.
- Виділення цілих рядків або цілих стовпців з датафрейму.
- Вибір підмножини рядків і стовпців з датафрейму за одну операцію.
- Вибір підмножини з датафрейму за єдиним булевим критерієм.
Датафрейми та серії у Pandas
Датафрейм (DataFrame) містить декілька серій (Series); Датафрейм — це спосіб представлення таблиці в Pandas, а серія — це структура даних, яку Pandas використовує для представлення окремого стовпця.
Pandas побудована на основі бібліотеки Numpy, що означає, що більшість методів для масивів Numpy також застосовується до датафреймів та серій у Pandas.
Що робить Pandas таким привабливим? Це потужний інтерфейс для доступу до окремих записів таблиці, належної обробки відсутніх значень та підтримки операцій з датафреймами, подібних до тих, що застосовуються в реляційних базах даних.
Вибір значень
Існує два способи доступу до значення в позиції [i,j] у
датафреймі, залежно від того, як інтерпретується i.
Пам’ятайте, що датафрейм використовує індекс для ідентифікації
рядків таблиці; отже, кожен рядок має позицію в таблиці, а
також заголовок рядка (мітку), яка однозначно визначає
цей рядок у датафреймі.
Використовуйте DataFrame.iloc[..., ...] для вибору
значень за їх позицією
- Можна вказати позицію значення за допомогою числового індексу аналогічно 2D-версії вибору символів у рядках.
PYTHON
import pandas as pd
data = pd.read_csv('data/gapminder_gdp_europe.csv', index_col='country')
print(data.iloc[0, 0])ВИВІД
1601.056136Використовуйте DataFrame.loc[..., ...] для доступу до
значень за їхніми мітками.
- Можна вказати розташування, використовуючи заголовок рядку та/або стовпця.
ВИВІД
1601.056136Використовуйте лише : замість мітки для позначення всіх
стовпців або всіх рядків.
- Це відповідає звичайному синтаксису зрізів у Python.
ВИВІД
gdpPercap_1952 1601.056136
gdpPercap_1957 1942.284244
gdpPercap_1962 2312.888958
gdpPercap_1967 2760.196931
gdpPercap_1972 3313.422188
gdpPercap_1977 3533.003910
gdpPercap_1982 3630.880722
gdpPercap_1987 3738.932735
gdpPercap_1992 2497.437901
gdpPercap_1997 3193.054604
gdpPercap_2002 4604.211737
gdpPercap_2007 5937.029526
Name: Albania, dtype: float64- Той самий результат можна отримати, використовуючи
data.loc["Albania"](без вказання другого індексу).
ВИВІД
country
Albania 1601.056136
Austria 6137.076492
Belgium 8343.105127
⋮ ⋮ ⋮
Switzerland 14734.232750
Turkey 1969.100980
United Kingdom 9979.508487
Name: gdpPercap_1952, dtype: float64- Той самий результат можна отримати, якщо надрукувати
data["gdpPercap_1952"] - Більш того, той самий результат можна отримати, застосовуючи нотацію
data.gdpPercap_1952(але не рекомендується, оскільки її легко сплутати з позначенням.для використання методів)
Вибирайте кілька стовпців або рядків за допомогою
DataFrame.loc та визначеного зрізу.
ВИВІД
gdpPercap_1962 gdpPercap_1967 gdpPercap_1972
country
Italy 8243.582340 10022.401310 12269.273780
Montenegro 4649.593785 5907.850937 7778.414017
Netherlands 12790.849560 15363.251360 18794.745670
Norway 13450.401510 16361.876470 18965.055510
Poland 5338.752143 6557.152776 8006.506993У наведеному вище коді ми бачимо, що зріз із використанням
loc включає дані на обох вказаних кінцях, на
відміну від зрізу із застосуванням iloc,
де зріз не включає кінцевий індекс.
Результат зрізу можна використовувати в подальших операціях.
- Зазвичай зрізи формуються не тільки для друку.
- Усі статистичні оператори, які працюють зі цілими фреймами даних, так само працюють зі зрізами.
- Наприклад, обчислення максимальних значень у зрізі.
ВИВІД
gdpPercap_1962 13450.40151
gdpPercap_1967 16361.87647
gdpPercap_1972 18965.05551
dtype: float64ВИВІД
gdpPercap_1962 4649.593785
gdpPercap_1967 5907.850937
gdpPercap_1972 7778.414017
dtype: float64Використовуйте операції порівняння для вибору даних на основі певного значення.
- Порівняння здійснюється поелементно.
- Повертає датафрейм подібної форми, що містить значення
TrueтаFalse.
PYTHON
# Використовуємо частину даних, щоб результат був читабельним
subset = data.loc['Italy':'Poland', 'gdpPercap_1962':'gdpPercap_1972']
print('Subset of data:\n', subset)
# Які значення перевищують 10000 ?
print('\nWhere are values large?\n', subset > 10000)ВИВІД
Subset of data:
gdpPercap_1962 gdpPercap_1967 gdpPercap_1972
country
Italy 8243.582340 10022.401310 12269.273780
Montenegro 4649.593785 5907.850937 7778.414017
Netherlands 12790.849560 15363.251360 18794.745670
Norway 13450.401510 16361.876470 18965.055510
Poland 5338.752143 6557.152776 8006.506993
Where are values large?
gdpPercap_1962 gdpPercap_1967 gdpPercap_1972
country
Italy False True True
Montenegro False False False
Netherlands True True True
Norway True True True
Poland False False FalseВибір значень або NaN за допомогою булевої маски.
- Датафрейм, що містить лише булеві значення, іноді називають маскою через спосіб його використання.
ВИВІД
gdpPercap_1962 gdpPercap_1967 gdpPercap_1972
country
Italy NaN 10022.40131 12269.27378
Montenegro NaN NaN NaN
Netherlands 12790.84956 15363.25136 18794.74567
Norway 13450.40151 16361.87647 18965.05551
Poland NaN NaN NaN- Результат містить оригінальні значення, коли умова виконується, та NaN (Not a Number - не число) у решті випадків.
- Це зручно, оскільки операції на кшталт max, min, average автоматично ігнорують значення NaN.
ВИВІД
gdpPercap_1962 gdpPercap_1967 gdpPercap_1972
count 2.000000 3.000000 3.000000
mean 13120.625535 13915.843047 16676.358320
std 466.373656 3408.589070 3817.597015
min 12790.849560 10022.401310 12269.273780
25% 12955.737547 12692.826335 15532.009725
50% 13120.625535 15363.251360 18794.745670
75% 13285.513523 15862.563915 18879.900590
max 13450.401510 16361.876470 18965.055510Group By: групує, застосовує та комбінує
Content from Побудова графіків
Останнє оновлення 2026-06-18 | Редагувати цю сторінку
Огляд
Питання
- Як побудувати графік за моїми даними?
- Як зберегти графік для публікації?
Цілі
- Створення графіку часового ряду, який відповідає одному набору даних.
- Створення точкової діаграми, або діаграми розсіювання, яка показує зв’язок між двома наборами даних.
matplotlib є
найпоширенішою науковою бібліотекою для візуалізації даних в
Python.
- Зазвичай використовується його частина - бібліотека
matplotlib.pyplot. - За замовчуванням Jupyter Notebook відображає графіки безпосередньо в блокноті.
- Створення простих графіків є (відносно) нескладним.
PYTHON
time = [0, 1, 2, 3]
position = [0, 100, 200, 300]
plt.plot(time, position)
plt.xlabel('Time (hr)')
plt.ylabel('Position (km)')
Зображення всіх графіків з програмного коду
У прикладі з Jupyter Notebook виконання комірки призводить до побудови графіку безпосередньо під кодом. Графік також зберігається у блокноті для подальшого перегляду. Проте, інші середовища Python, такі як інтерактивна сесія Python, що виконується у терміналі, або Python скрипт, виконаний за допомогою командного рядка, потребують додаткової команди для зображення графіку.
Доручіть matplotlib зобразити графік:
Цю команду також можна використати в блокноті - наприклад, для зображення декількох графіків одночасно, якщо відповідний командний код міститься в одній комірці.
Побудова графіків безпосередньо з датафреймів Pandas.
- Для побудови графіків можна також використовувати датафрейми Pandas.
- Перед побудовою графіку ми перетворюємо назви стовпців із типу
stringнаinteger, оскільки вони представляють числові значення. Для цього використовуємо метод str.replace(), щоб видалити префіксgpdPercap_, а потім astype(int), щоб перетворити ряд значень рядка (['1952', '1957', ...'2007']) у ряд цілих чисел:[1925, 1957, ..., 2007].
PYTHON
import pandas as pd
data = pd.read_csv('data/gapminder_gdp_oceania.csv', index_col='country')
# Extract year from last 4 characters of each column name
# The current column names are structured as 'gdpPercap_(year)',
# so we want to keep the (year) part only for clarity when plotting GDP vs. years
# To do this we use replace(), which removes from the string the characters stated in the argument
# This method works on strings, so we use replace() from Pandas Series.str vectorized string functions
years = data.columns.str.replace('gdpPercap_', '')
# Convert year values to integers, saving results back to dataframe
data.columns = years.astype(int)
data.loc['Australia'].plot()
Виділіть та трансформуйте дані, а потім побудуйте графік.
- За замовчуванням,
DataFrame.plotзображує рядки на осі X. - Ми можемо транспонувати дані, щоб побудувати кілька графіків разом.

Доступні багато стилів графіків.
- Наприклад, можна створити стовпчикову діаграму з більш вишуканим стилем.

Графік також можна побудувати, викликавши безпосередньо функцію
plot бібліотеки matplotlib.
- Формат команди є таким:
plt.plot(x, y) - Колір та формат маркерів також можна вказати як додатковий
необов’язковий аргумент, тобто,
b-- це синя лінія,g--- це зелена пунктирна лінія.
Отримаємо дані Австралії з датафрейму.
PYTHON
years = data.columns
gdp_australia = data.loc['Australia']
plt.plot(years, gdp_australia, 'g--')
Можна побудувати кілька графіків за різними наборами даних одночасно.
PYTHON
# Select two countries' worth of data.
gdp_australia = data.loc['Australia']
gdp_nz = data.loc['New Zealand']
# Plot with differently-colored markers.
plt.plot(years, gdp_australia, 'b-', label='Australia')
plt.plot(years, gdp_nz, 'g-', label='New Zealand')
# Create legend.
plt.legend(loc='upper left')
plt.xlabel('Year')
plt.ylabel('GDP per capita ($)')Додавання легенди
Зазвичай при побудові графіків з кількох наборів даних разом, бажано мати легенду, що описує ці дані.
Це можна зробити в matplotlib за два етапи:
- Вкажіть мітку для кожного набору даних у графіку:
PYTHON
plt.plot(years, gdp_australia, label='Australia')
plt.plot(years, gdp_nz, label='New Zealand')- Доручіть
matplotlibстворити легенду.
За замовчуванням matplotlib спробує розмістити легенду у відповідному
місці. Якщо необхідно вказати конкретне розташування, можна застосувати
аргументи функції loc=, наприклад, щоб розмістити легенду в
лівому верхньому куті графіку, задайте loc='upper left'

- Побудуйте точкову діаграму співвідношення ВВП Австралії та Нової Зеландії
- Використовуйте
plt.scatterабоDataFrame.plot.scatter


Мінімуми та максимуми
Заповніть порожні поля нижче, щоб побудувати графік мінімального ВВП на душу населення протягом часу для всіх країн Європи. Потім побудуйте графік максимального ВВП на душу населення в Європі.
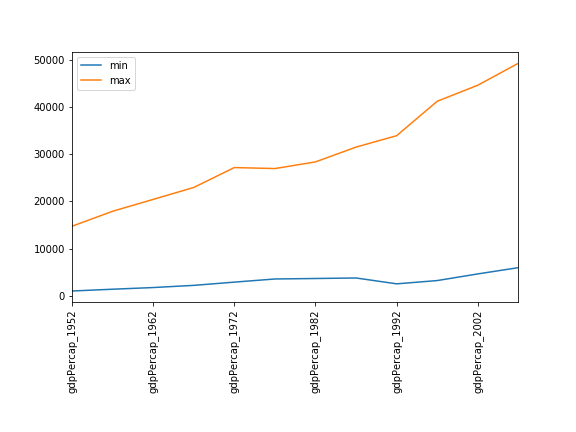
Співвідношення
Модифікуйте приклад у примітках, щоб створити діаграму розсіювання, що показує співвідношення між мінімальним і максимальним ВВП на душу населення серед країн Азії за кожен рік у наборі даних. Який зв’язок ви бачите (якщо такий є)?
PYTHON
data_asia = pd.read_csv('data/gapminder_gdp_asia.csv', index_col='country')
data_asia.describe().T.plot(kind='scatter', x='min', y='max')
Між мінімальним і максимальним значеннями ВВП за роками не спостерігається чіткої залежності. Здається, статки азійських країн не зростають і не падають разом.
Співвідношення (continued)
Ви можете помітити, що варіабельність максимальних значень значно вища, ніж варіабельність мінімальних значень. Зверніть увагу на максимальні значення та відповідні індекси:
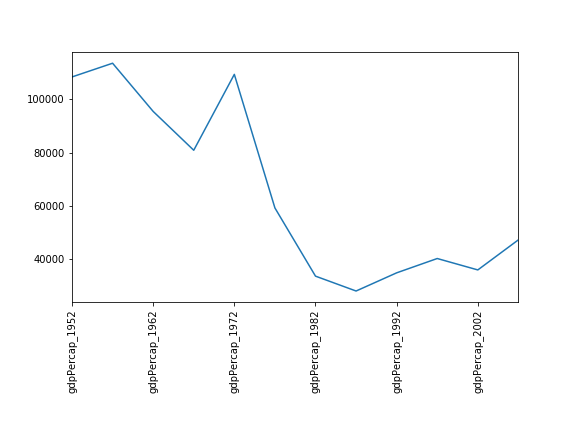
Здається, варіабельність цього значення зумовлена різким спадом після 1972 року. Можливо, тут зіграли роль геополітичні чинники? Враховуючи домінування нафтовидобувних країн, можливо, індекс нафти Brent стане цікавим об’єктом для порівняння? У той час як М’янма постійно має найнижчий ВВП, країна з найвищим ВВП змінюється більш помітно.
Більше кореляцій
Ця коротка програма створює графік, який ілюструє взаємозв’язок між ВВП і очікуваною тривалістю життя на 2007 рік, змінюючи розмір маркера в залежності із чисельністю населення:
PYTHON
data_all = pd.read_csv('data/gapminder_all.csv', index_col='country')
data_all.plot(kind='scatter', x='gdpPercap_2007', y='lifeExp_2007',
s=data_all['pop_2007']/1e6)Використовуючи онлайн-довідку та інші ресурси, поясніть роль кожного аргументу, який передається у функцію plot.

Гарне місце для пошуку документації до функції plot - help(data_all.plot).
kind - Як вже було показано, цей параметр визначає тип графіку, який буде створено.
x та y - імена стовпців або індекси, що визначають, які дані будуть розміщені на графіку на осях x та y
s - Інформацію про цей аргумент можна знайти в документації plt.scatter. Це одне число або одне значення для кожної точки даних. Визначає розмір маркера.
Збереження вашого графіка в файл
Якщо вас влаштовує побудований графік, можливо, ви захочете зберегти його у файл — наприклад, для включення у публікацію. У модулі matplotlib.pyplot є функція, яка виконує це: savefig. Виклик цієї функції
збереже поточний графік у файл my_figure.png. Формат
файлу буде автоматично визначено з розширення імені файлу (інші формати:
pdf, ps, eps і svg).
Зауважимо, що функції в plt посилаються на глобальну
змінну графіка і після того, як графік виведено на екран (наприклад, за
допомогою plt.show) matplotlib змусить цю змінну посилатися
на новий порожній графік. Тому переконайтеся, що ви викликаєте
plt.savefig перед тим, як графік буде зображено на екрані,
інакше ви можете створити файл із порожнім графіком.
При використанні датафреймів дані зазвичай генеруються та виводяться
на екрані одним рядком коду. На додаток до plt.savefig, ми
можемо зберегти посилання на поточний графік у локальну змінну
(використовуючи plt.gcf), а потім викликати
savefig метод цієї змінної для збереження графіка у
файл.
Зробіть ваш графік доступним
Щоразу, коли ви створюєте графіки для статті чи презентації, варто врахувати кілька речей, щоб переконатися, що всі зрозуміють ваші графіки.
- Завжди стежте за тим, щоб розмір тексту був зручним для читання.
Використовуйте параметр
fontsizeвxlabel,ylabel,title, таlegend, а такожtick_paramsзlabelsizeщоб збільшити розмір тексту на осях графіку. - Також слід подбати, щоб елементи графіка були добре помітними.
Використовуйте
s, щоб збільшити розмір маркерів діаграми розсіювання, іlinewidth, щоб збільшити розміри ліній вашого графіка. - Якщо розрізняти елементи графіка тільки за кольором, це може
ускладнити його сприйняття для людей із дальтонізмом або тих, хто
переглядає матеріали в чорно-білому вигляді (наприклад, після друку).
Для ліній можна використовувати параметр
linestyle, щоб задати різні стилі ліній. Для діаграм розсіюванняmarkerдозволяє змінювати форму ваших точок. Якщо ви не впевнені у вибраній кольоровій палітрі, скористайтеся інструментами на кшталт Coblis або Color Oracle щоб імітувати, як виглядатимуть ваші графіки для людей з дальтонізмом.
-
matplotlib— це найпоширеніша наукова бібліотека для побудови графіків у Python. - Будуйте графіки безпосередньо з датафрейму Pandas.
- Побудова графіків включає вибір та трансформацію даних.
- Існує широкий вибір стилів побудови графіків: дивіться Python Graph Gallery, щоб ознайомитися з іншими варіантами.
- На одному графіку можна одразу зобразити кілька наборів даних.
Content from Ланч
Останнє оновлення 2026-06-18 | Редагувати цю сторінку
За обідом поміркуйте та обговоріть наступне:
- Які пакети можна використовувати в Python, і чому ми їх використовуємо?
- Як мають бути відформатовані дані, щоб використовувати їх у датафреймах Pandas? Чи задовольняють ваші поточні дані ці вимоги?
- З якими обмеженнями або проблемами ви можете зустрітися, якщо спробуєте застосувати набуті знання до ваших власних проєктів або даних?
Content from Списки
Останнє оновлення 2026-06-18 | Редагувати цю сторінку
Огляд
Питання
- Як ефективно зберігати багато значень?
Цілі
- Пояснити, навіщо програмам потрібна можливість працювати з наборами значень.
- Написати програми, які створюють списки, індексують їх, отримують зрізи, а також змінюють списки через присвоєння значень та виклик методів.
За допомогою списків можна зберігати кілька значень в одній структурі даних.
- Виконання обчислень із сотнею змінних під назвою
pressure_001,pressure_002тощо, було б принаймні так само повільно, як робити їх вручну. - Використовуйте список для зберігання багатьох значень разом.
- Список позначається квадратними дужками
[...]. - Значення розділяються комами
,.
- Список позначається квадратними дужками
- Використовуйте
len, щоб дізнатися, скільки значень у списку.
PYTHON
pressures = [0.273, 0.275, 0.277, 0.275, 0.276]
print('pressures:', pressures)
print('length:', len(pressures))ВИВІД
pressures: [0.273, 0.275, 0.277, 0.275, 0.276]
length: 5Щоб отримати елемент списку, використовуйте його індекс.
- Це робиться так само, як і при роботі з рядками.
PYTHON
print('zeroth item of pressures:', pressures[0])
print('fourth item of pressures:', pressures[4])ВИВІД
zeroth item of pressures: 0.273
fourth item of pressures: 0.276Значення елементів списків можна замінити шляхом присвоєння.
- Використовуйте індексний вираз ліворуч від знаку присвоєння, щоб замінити значення.
ВИВІД
Нові значення pressures: [0.265, 0.275, 0.277, 0.275, 0.276]Додавання елементів до списку подовжує його.
- Щоб додати елементи в кінець списку, використовуйте
list_name.append.
PYTHON
primes = [2, 3, 5]
print('Початкові значення primes:', primes)
primes.append(7)
print('Список primes змінився:', primes)ВИВІД
Початкові значення primes: [2, 3, 5]
Список primes змінився: [2, 3, 5, 7]-
appendє методом списків.- Методи подібні функціям, але вони прив’язані до певних об’єктів.
- Для виклику методів використовується синтаксис
object_name.method_name.- Такий запис навмисно відтворює те, як ми звертаємося до функцій у бібліотеці.
- По ходу роботи ми познайомимося з іншими методами, визначеними для
списків.
- Використовуйте
help(list), якщо бажаєте переглянути їх перелік зараз.
- Використовуйте
-
extend- це метод, схожий наappend, але він дозволяє об’єднувати два списки. Наприклад:
PYTHON
teen_primes = [11, 13, 17, 19]
middle_aged_primes = [37, 41, 43, 47]
print('primes is currently:', primes)
primes.extend(teen_primes)
print('primes has now become:', primes)
primes.append(middle_aged_primes)
print('primes has finally become:', primes)ВИВІД
primes is currently: [2, 3, 5, 7]
primes has now become: [2, 3, 5, 7, 11, 13, 17, 19]
primes has finally become: [2, 3, 5, 7, 11, 13, 17, 19, [37, 41, 43, 47]]Зауважимо, що extend зберігає “плоску” структуру списку,
тоді як додавання списку до іншого списку за допомогою
append дає двовимірний результат: останній елемент з
primes є списком, а не цілим числом. Списки можуть містити
значення будь-якого типу; отже, можливі списки списків.
Використовуйте del для повного видалення елементів зі
списку.
- Ми використовуємо
del list_name[index]для видалення елемента зі списку (у прикладі нижче, 9 не є простим числом) і таким чином скоротити список. -
del- це не функція і не метод, а оператор мови Python.
PYTHON
primes = [2, 3, 5, 7, 9]
print('primes перед видаленням останнього елементу:', primes)
del primes[4]
print('primes після видалення останнього елементу:', primes)ВИВІД
primes перед видаленням останнього елементу: [2, 3, 5, 7, 9]
primes після видалення останнього елементу: [2, 3, 5, 7]Порожній список не містить жодних значень.
- Щоб створити порожній список, використовуйте
[].- Порожній список - це “нуль списків.”
- Корисний як початкова структура для накопичення значень (як ми побачимо в наступному епізоді).
Списки можуть містити значення різних типів.
- Один список може містити числа, рядки та будь-що інше.
Рядки символів можна індексувати як списки.
- Отримати окремі символи з рядка символів можна за допомогою індексів у квадратних дужках.
ВИВІД
нульовий символ: c
третій символ: bРядки символів незмінні.
- Неможливо змінити символи в рядку після його створення.
- Незмінний (Immutable): не може бути змінений після створення.
- На відміну від рядків, списки можна змінювати після їх створення.
- Python розглядає рядок як одне значення, яке складається з частин, а не як набір незалежних значень.
ПОМИЛКА
TypeError: 'str' object does not support item assignment- Списки та рядки символів є колекціями.
Індексація після кінця колекції призводить до помилки.
- Python повідомляє про помилку
IndexError, якщо ми намагаємося звернутися до не наявного значення.- Це різновид помилки виконання (runtime error).
- Її неможливо виявити під час аналізу коду, оскільки індекс може бути розрахований на основі даних, з якими працює програма.
ВИВІД
IndexError: string index out of rangeЯкий розмір має зріз?
Якщо start і stop є невід’ємними цілими
числами, якою є довжина списку values[start:stop:]?
Список values[start:stop] може містити щонайбільше
stop - start елементів. Наприклад, values[1:4]
має 3 елементи values[1], values[2], та
values[3]. Чому ‘щонайбільше’? Як ми бачили у епізоді 2, якщо stop перевищує
загальну довжину списку values, результатом усе одно буде
список, але коротший, ніж очікувалося.
list('some string')перетворює рядок на список окремих символів.joinповертає рядок, який є конкатенацією всіх елементів, та додає роздільник між кожним елементом у списку. У результаті отримуємоx-y-z. Рядок, який викликає цей метод, виступає роздільником між елементами.
Робота з кінцем
Що друкує наступна програма?
- Як Python інтерпретує від’ємний індекс?
- Якщо список або рядок має N елементів, який найбільший від’ємний індекс можна безпечно використовувати для даного рядка, і яку позицію він означає?
- Якщо
valuesє списком, що відбувається при виконанніdel values[-1]? - Як можна показати всі елементи, окрім останнього, не змінюючи
values? (Підказка: вам знадобиться одночасно використати зрізи та від’ємну індексацію.)
Програма надрукує m.
Python інтерпретує від’ємний індекс як відлік з кінця (на відміну від звичайного відліку з початку). Останній елемент має індекс
-1.Найменший від’ємний індекс, який можна безпечно використовувати зі списком із N елементів - це індекс
-N, який представляє перший елемент.del values[-1]видаляє останній елемент зі списку.values[:-1]
Програма виводить
strideє довжиною кроку зрізу.Зріз
1::2вибирає всі елементи з парними номерами з колекції: він починається з елементу1(який є другим елементом, оскільки індексація починається з0), продовжується до кінця (оскількиendне задано) і використовує розмір кроку2(таким чином обираючи кожний другий елемент).
ВИВІД
lithiumПерша команда повертає весь рядок, оскільки зріз перевищує загальну довжину рядка. Друга команда повертає порожній рядок, оскільки зріз виходить “за межі” рядка.
Програма А надрукує
ВИВІД
letters is ['g', 'o', 'l', 'd'] and result is ['d', 'g', 'l', 'o']Програма В надрукує
ВИВІД
letters is ['d', 'g', 'l', 'o'] and result is Nonesorted(letters) повертає відсортовану копію списку
letters (оригінальний список letters
залишається незмінним), тоді як letters.sort() сортує
список letters безпосередньо і нічого не повертає.
Програма А надрукує
ВИВІД
new is ['D', 'o', 'l', 'd'] and old is ['D', 'o', 'l', 'd']Програма В надрукує
ВИВІД
new is ['D', 'o', 'l', 'd'] and old is ['g', 'o', 'l', 'd']Оператор new = old призводить до того, що
new посилається на той самий об’єкт списку, що й
old.
Однак new = old[:] навпаки створює окремий список
new, який містить усі елементи зі списку old;
тому new та old є різними об’єктами.
- За допомогою списків можна зберігати кілька значень в одній структурі даних.
- Щоб отримати елемент списку, використовуйте його індекс.
- Значення елементів списків можна замінити шляхом присвоєння.
- Додавання елементів до списку подовжує його.
- Щоб повністю видалити елементи зі списку, використовуйте
del. - Порожній список не містить жодних значень.
- Списки можуть містити значення різних типів.
- Рядки символів можна індексувати як списки.
- Рядки символів незмінні.
- Звернення до індексу за межами колекції призводить до помилки.
Content from Цикли for
Останнє оновлення 2026-06-18 | Редагувати цю сторінку
Огляд
Питання
- Як змусити програму ефективно виконувати багато задач?
Цілі
- Пояснити, для чого зазвичай використовуються цикли for.
- Проаналізувати виконання простого (не вкладеного) циклу та правильно вказати значення змінних у кожній ітерації.
- Написати цикли for, які використовують шаблон накопичення для агрегації значень.
Цикл for виконує команди один раз для кожного значення в колекції.
- Виконання обчислень над елементами списку окремо є таким самим
виснажливим, як і робота зі змінними на кшталт
pressure_001,pressure_002і так далі. - Цикл for вказує Python, що треба виконати набір інструкцій для кожного елемента списку, рядка або іншої колекції.
- “для кожного елемента в цій групі виконайте ці операції”
- Цей цикл
forє еквівалентним наступному:
- І результат циклу
forє таким:
ВИВІД
2
3
5Цикл for складається з колекції, змінної циклу та тіла
циклу.
- Колекція
[2, 3, 5]- це те, що опрацьовується в циклі. - Тіло циклу,
print(number), визначає, що робити для кожного значення в колекції. - Змінна циклу,
number, змінюється для кожної ітерації циклу.- Це - “поточне значення”.
Перший рядок циклу for має закінчуватися двокрапкою, а
тіло циклу має бути з відступом.
- Двокрапка в кінці першого рядка вказує на початок блоку операторів.
- Python використовує відступи замість
{}абоbegin/end, щоб показати вкладеність.- Будь-яке послідовне використання відступів є допустимим, але зазвичай використовують чотири пробіли.
ПОМИЛКА
IndentationError: expected an indented block- Відступи у Python завжди важливі.
ПОМИЛКА
File "<ipython-input-7-f65f2962bf9c>", line 2
lastName = "Smith"
^
IndentationError: unexpected indent- Ця помилка може бути виправлена шляхом видалення зайвих пробілів на початку другого рядку.
Змінні циклу можна називати як завгодно.
- Як і всі інші змінні, змінні циклу:
- Створюються за потреби
- Не несуть смислового навантаження: їх імена можуть бути будь-якими.
Тіло циклу може містити багато операторів.
- Але жоден цикл не повинен мати довжину більше кількох рядків.
- Людям важко утримувати у пам’яті великі фрагменти коду.
ВИВІД
2 4 8
3 9 27
5 25 125Використовуйте range для перебору послідовності
чисел.
- Вбудована функція
rangeстворює послідовність чисел.- Це не список: числа генеруються за потребою, щоб зробити перебір по великих діапазонах ефективнішим.
-
range(N)є послідовністю чисел від 0 до N-1 включно.- Це в точності збігається з індексами списку або рядка символів довжиною N.
ВИВІД
a range is not a list: range(0, 3)
0
1
2Шаблон накопичення перетворює набір значень на одне підсумкове.
- Поширений алгоритм, який можна побачити у програмах:
- Надати початкове значення для накопичувальної змінної: нуль, порожній рядок або порожній список.
- Оновлення змінної значеннями з колекції.
PYTHON
# Знайти суму перших 10 цілих чисел.
total = 0
for number in range(10):
total = total + (number + 1)
print(total)ВИВІД
55- Команда
total = total + (number + 1)інтерпретується наступним чином:- Додати 1 до поточного значення змінної циклу
number. - Додати це до поточного значення змінної-накопичувача
total. - Присвоїти результат змінній
total, замінивши її поточне значення.
- Додати 1 до поточного значення змінної циклу
- Ми маємо додавати
number + 1, тому щоrangeгенерує значення 0..9, а не 1..10.
Класифікація помилок
Чи є помилка відступу (indentation error) синтаксичною помилкою чи помилкою виконання?
IndentationError є синтаксичною помилкою. Програми з синтаксичними помилками неможливо запустити. Програма з помилкою виконання запускається, але за певних умов видається помилка.
| Номер рядка | Значення змінних |
|---|---|
| 1 | total = 0 |
| 2 | total = 0 char = ‘t’ |
| 3 | total = 1 char = ‘t’ |
| 2 | total = 1 char = ‘i’ |
| 3 | total = 2 char = ‘i’ |
| 2 | total = 2 char = ‘n’ |
| 3 | total = 3 char = ‘n’ |
Практика використання шаблону накопичення (continued)
Створіть акронім: За допомогою циклу
for сформуйте акронім "RGB" зі списку
["red", "green", "blue"].
Підказка: Для правильного форматування акроніма може знадобитися один з методів, які визначені для рядків.
Накопичувальна сума
Перегрупуйте та правильно розставте відступи в рядках коду нижче, щоб
програма вивела новий список, у якому i-тий елемент є сумою
усіх елементів з першого до i-го включно зі списку
data. Результатом має бути [1, 3, 5, 10].
Виявлення помилок в іменах змінних
- Прочитайте наведений нижче код і спробуйте знайти помилки без запуску програми.
- Запустіть код і прочитайте повідомлення про помилку. Як ви думаєте,
який це тип
NameError? Це рядок без лапок, змінна з орфографічною помилкою чи змінна, яку не було попередньо визначено? - Виправте помилку.
- Повторюйте кроки 2 і 3, доки не виправите всі помилки.
- Імена змінних у Python чутливі до регістру:
numberтаNumberвказують на різні змінні. - Змінна
messageмає бути ініціалізована як порожній рядок. - Потрібно додати рядок з вмістом
"a"доmessage, а не невизначену зміннуa.
Виявлення помилок індексації
- Цикл
forвиконує команди один раз для кожного значення в колекції. - Цикл
forскладається з колекції, змінної циклу та тіла циклу. - Перший рядок циклу
forмає закінчуватися двокрапкою, а тіло циклу має бути з відступом. - Відступи у Python завжди мають значення.
- Змінні циклу можна назвати як завгодно (але бажано, щоб їх назва була змістовною).
- Тіло циклу може містити багато операторів.
- Використовуйте
rangeдля перебору послідовності чисел. - Шаблон накопичення перетворює набір значень на одне підсумкове.
Content from Умовні оператори
Останнє оновлення 2026-06-18 | Редагувати цю сторінку
Огляд
Питання
- Як програми можуть виконувати різні дії для різних даних?
Цілі
- Правильно писати програми, які використовують оператори
ifтаelse, та прості булеві вирази (без логічних операторів). - Відстежувати виконання невкладених умовних операторів і умовних операторів всередині циклів.
Використовуйте команди if, щоб контролювати, чи
виконується блок коду.
- Оператор
if(правильна назва - умовний оператор) контролює, чи буде виконано певний блок коду. - Його синтаксис подібний до синтаксису оператора
for:- Перший рядок починається з `if’ і закінчується двокрапкою
- Блок коду оператора, що містить одну або кілька команд, має відступ (зазвичай на 4 пробіли)
PYTHON
mass = 3.54
if mass > 3.0:
print(mass, 'is large')
mass = 2.07
if mass > 3.0:
print (mass, 'is large')ВИВІД
3.54 is largeУмовні оператори часто використовуються всередині циклів.
- Немає особливого сенсу використовувати умовний оператор, коли ми знаємо точне значення (як у прикладі вище).
- Але це корисно, коли у нас є колекція, яку треба проаналізувати.
ВИВІД
3.54 is large
9.22 is largeВикористовуйте else для виконання блоку коду, коли
умова if не виконується.
-
elseможна використовувати післяif. - Це дозволяє вказати альтернативні дії, коли умова гілки
ifне виконується.
PYTHON
masses = [3.54, 2.07, 9.22, 1.86, 1.71]
for m in masses:
if m > 3.0:
print(m, 'is large')
else:
print(m, 'is small')ВИВІД
3.54 is large
2.07 is small
9.22 is large
1.86 is small
1.71 is smallВикористовуйте elif для додаткових перевірок.
- У разі потреби можна надати кілька альтернативних варіантів, кожен з яких має власну умову для виконання.
- Використовуйте
elif(скорочення від “else if”) та відповідну умову для перевірки. - Завжди асоціюється з
if. - Має йти перед
else(що починає блок, який охоплює всі інші випадки).
PYTHON
masses = [3.54, 2.07, 9.22, 1.86, 1.71]
for m in masses:
if m > 9.0:
print(m, 'is HUGE')
elif m > 3.0:
print(m, 'is large')
else:
print(m, 'is small')ВИВІД
3.54 is large
2.07 is small
9.22 is HUGE
1.86 is small
1.71 is smallУмови перевіряються один раз, послідовно.
- Python послідовно проходить гілки умовного оператора, перевіряючи кожну по черзі.
- Отже, порядок перевірки має значення.
PYTHON
grade = 85
if grade >= 90:
print('grade is A')
elif grade >= 80:
print('grade is B')
elif grade >= 70:
print('grade is C')ВИВІД
grade is B- Програма не повертається назад автоматично і не переоцінює значення, якщо вони змінюються.
PYTHON
velocity = 10.0
if velocity > 20.0:
print('moving too fast')
else:
print('adjusting velocity')
velocity = 50.0ВИВІД
adjusting velocity- Умовні оператори часто використовуються в циклі для послідовної зміни значень змінних.
PYTHON
velocity = 10.0
for i in range(5): # execute the loop 5 times
print(i, ':', velocity)
if velocity > 20.0:
print('moving too fast')
velocity = velocity - 5.0
else:
print('moving too slow')
velocity = velocity + 10.0
print('final velocity:', velocity)ВИВІД
0 : 10.0
moving too slow
1 : 20.0
moving too slow
2 : 30.0
moving too fast
3 : 25.0
moving too fast
4 : 20.0
moving too slow
final velocity: 30.0Створіть таблицю зі значеннями змінних для відстеження виконання програми.
| i | 0 | . | 1 | . | 2 | . | 3 | . | 4 | . |
| velocity | 10.0 | 20.0 | . | 30.0 | . | 25.0 | . | 20.0 | . | 30.0 |
- Програма повинна мати оператор
printпоза тілом циклу, щоб вивести кінцеве значенняvelocity, оскільки його значення оновлюється під час останньої ітерації циклу.
Складені логічні вирази з використанням
and, or та дужок
Часто потрібно перевірити, що виконується певна сукупність умов.
Логічні вирази можна комбінувати в умовному операторі за допомогою
and та or. Продовжуючи попередній приклад,
застосуємо комбінацію перевірок значень зі списків mass та
velocity в умовному операторі:
PYTHON
mass = [ 3.54, 2.07, 9.22, 1.86, 1.71]
velocity = [10.00, 20.00, 30.00, 25.00, 20.00]
i = 0
for i in range(5):
if mass[i] > 5 and velocity[i] > 20:
print("Fast heavy object. Duck!")
elif mass[i] > 2 and mass[i] <= 5 and velocity[i] <= 20:
print("Normal traffic")
elif mass[i] <= 2 and velocity[i] <= 20:
print("Slow light object. Ignore it")
else:
print("Whoa! Something is up with the data. Check it")Як і в арифметичних виразах, дужки слід використовувати скрізь, де
може виникнути неоднозначність. Надійне правило: завжди розставляти
дужки при одночасному використанні and та or в
одній умові. Таким чином, замість:
слід використовувати один з наступних варіантів:
PYTHON
if (mass[i] <= 2 or mass[i] >= 5) and velocity[i] > 20:
if mass[i] <= 2 or (mass[i] >= 5 and velocity[i] > 20):внаслідок чого читачеві (а також інтерпретатору Python) буде цілком зрозуміло, що ви насправді маєте на увазі.
ВИВІД
25.0Аналіз списку
Заповніть порожні поля в програмі таким чином, щоб результатом її виконання був новий список, у якому від’ємні елементи вихідного списку замінено на нулі, а додатні — на одиниці.
PYTHON
original = [-1.5, 0.2, 0.4, 0.0, -1.3, 0.4]
result = ____
for value in original:
if ____:
result.append(0)
else:
____
print(result)ВИВІД
[0, 1, 1, 1, 0, 1]Ініціалізація
Змініть цю програму так, щоб знайти найбільше та найменше значення у списку незалежно від початкового діапазону значень.
PYTHON
values = [...деякі тестові дані...]
smallest, largest = None, None
for v in values:
if ____:
smallest, largest = v, v
____:
smallest = min(____, v)
largest = max(____, v)
print(smallest, largest)Які переваги та недоліки притаманні цьому методу визначення діапазону даних?
PYTHON
values = [-2,1,65,78,-54,-24,100]
smallest, largest = None, None
for v in values:
if smallest is None and largest is None:
smallest, largest = v, v
else:
smallest = min(smallest, v)
largest = max(largest, v)
print(smallest, largest)Якщо ви напишете == None замість is None,
це теж працює, але програмісти Python завжди пишуть is None
через особливий спосіб обробки None у цій мові.
Можна стверджувати, що перевагою цього методу є краща читабельність
коду. Однак недоліком є те, що цей код не є ефективним, оскільки в
кожній ітерації циклу for виконуються ще два цикли, кожен з
яких опрацьовує два числа (це функції min і
max). Було б ефективніше опрацьовувати кожне число лише
один раз:
PYTHON
values = [-2,1,65,78,-54,-24,100]
smallest, largest = None, None
for v in values:
if smallest is None or v < smallest:
smallest = v
if largest is None or v > largest:
largest = v
print(smallest, largest)Тепер маємо один цикл, але чотири тестові порівняння. Подальше вдосконалення можливе двома шляхами: скоротити кількість порівнянь на кожній ітерації або використати два цикли, кожен з яких містить лише одне порівняння. Найпростіше рішення часто є найкращим:
- Використовуйте оператор
if, щоб контролювати, чи виконується відповідний блок коду. - Умовні оператори часто використовуються всередині циклів.
- Використовуйте
elseдля виконання блоку коду, коли умоваifне виконується. - Використовуйте
elifдля визначення додаткових перевірок. - Умови перевіряються один раз, послідовно.
- Створюйте таблицю зі значеннями змінних для відстеження виконання програми.
Content from Обробка багатьох файлів у циклі
Останнє оновлення 2026-06-18 | Редагувати цю сторінку
Огляд
Питання
- Як обробляти багато наборів даних за допомогою однієї команди?
Цілі
- Навчитися читати та писати вирази модулю glob, які визначають набори файлів.
- Використовувати модуль glob для створення списків файлів
- Створювати цикли
forдля виконання операцій зі списком файлів.
Використовуйте цикл for для послідовної обробки файлів,
імена яких містяться у списку.
- Ім’я файлу - це рядок символів.
- Списки, своєю чергою, можуть містити рядки символів.
PYTHON
import pandas as pd
for filename in ['data/gapminder_gdp_africa.csv', 'data/gapminder_gdp_asia.csv']:
data = pd.read_csv(filename, index_col='country')
print(filename, data.min())ВИВІД
data/gapminder_gdp_africa.csv gdpPercap_1952 298.846212
gdpPercap_1957 335.997115
gdpPercap_1962 355.203227
gdpPercap_1967 412.977514
⋮ ⋮ ⋮
gdpPercap_1997 312.188423
gdpPercap_2002 241.165877
gdpPercap_2007 277.551859
dtype: float64
data/gapminder_gdp_asia.csv gdpPercap_1952 331
gdpPercap_1957 350
gdpPercap_1962 388
gdpPercap_1967 349
⋮ ⋮ ⋮
gdpPercap_1997 415
gdpPercap_2002 611
gdpPercap_2007 944
dtype: float64Використовуйте glob.glob,
щоб знайти набори файлів, імена яких відповідають шаблону.
- В Unix термін “globbing” означає “відповідність набору файлів шаблону”.
- Найпоширеніші шаблони:
-
*означає “відповідати нулю або більшій кількості символів” -
?означає “відповідати в точності одному символу”
-
- Стандартна бібліотека Python містить модуль
globдля роботи з наборами файлів, які задані за допомогою шаблонів - Модуль
globмістить функцію, яка також називаєтьсяglob, для відбору файлів за шаблоном. - Наприклад,
glob.glob('*.txt')знайде всі файли в поточному каталозі, імена яких закінчуються на.txt. - Результатом є (можливо, порожній) список рядків символів.
ВИВІД
all csv files in data directory: ['data/gapminder_all.csv', 'data/gapminder_gdp_africa.csv', \
'data/gapminder_gdp_americas.csv', 'data/gapminder_gdp_asia.csv', 'data/gapminder_gdp_europe.csv', \
'data/gapminder_gdp_oceania.csv']ВИВІД
all PDB files: []Використовуйте glob та for для обробки
груп файлів.
- Систематичне та послідовне іменування файлів — запорука ефективного пошуку за шаблонами.
PYTHON
for filename in glob.glob('data/gapminder_*.csv'):
data = pd.read_csv(filename)
print(filename, data['gdpPercap_1952'].min())ВИВІД
data/gapminder_all.csv 298.8462121
data/gapminder_gdp_africa.csv 298.8462121
data/gapminder_gdp_americas.csv 1397.717137
data/gapminder_gdp_asia.csv 331.0
data/gapminder_gdp_europe.csv 973.5331948
data/gapminder_gdp_oceania.csv 10039.59564- Перелік має файл
data/gapminder_all.csvз усіма даними, а також файли з даними по окремих регіонах. - У вправах нижче використовуйте більш точний шаблон. Це дозволить
виключити загальний набір даних
data/gapminder_all.csvі відібрати лише файли для окремих регіонів. - Слід зазначити, що мінімум у файлі
data/gapminder_all.csvзбігається з мінімумом одного з менших файлів. Це є гарною перевіркою результату.
Розуміння шаблонів
Який із цих файлів не відповідає виразу
glob.glob('data/*as*.csv')?
data/gapminder_gdp_africa.csvdata/gapminder_gdp_americas.csvdata/gapminder_gdp_asia.csv
Заданому шаблону не відповідає перший з файлів.
Мінімальний розмір файлу
Змініть цю програму, щоб вона визначала та виводила мінімальну кількість записів серед усіх файлів.
PYTHON
import glob
import pandas as pd
fewest = ____
for filename in glob.glob('data/*.csv'):
dataframe = pd.____(filename)
fewest = min(____, dataframe.shape[0])
print('smallest file has', fewest, 'records')Зверніть увагу, що метод DataFrame.shape()
повертає кортеж (tuple), елементами якого є кількість рядків та
кількість стовпців у датафреймі.
PYTHON
import glob
import pandas as pd
fewest = float('Inf')
for filename in glob.glob('data/*.csv'):
dataframe = pd.read_csv(filename)
fewest = min(fewest, dataframe.shape[0])
print('smallest file has', fewest, 'records')Можна було б ініціалізувати змінну fewest числом, що
перевищує всі числа у наборі даних, однак це може спричинити помилки при
повторному використанні коду з більшими числами. Python дозволяє
використати додатну нескінченність, яка буде працювати незалежно від
значень ваших чисел. Які інші спеціальні рядки розпізнає функція
float?
Порівняння даних
Напишіть програму, яка читає регіональні набори даних і будує графік середнього ВВП на душу населення для кожного регіону в часі в одній діаграмі. Pandas видасть помилку, якщо зустріне при цьому нечислові стовпці, тому ви маєте або відфільтрувати ці стовпці, або вказати Pandas ігнорувати їх.
Це рішення створює корисну легенду за допомогою методу
split для рядків для вилучення region зі
шляху ’data/gapminder\_gdp\_a\_specific\_region.csv’.
PYTHON
import glob
import pandas as pd
import matplotlib.pyplot as plt
fig, ax = plt.subplots(1,1)
for filename in glob.glob('data/gapminder_gdp*.csv'):
dataframe = pd.read_csv(filename)
# Вилучаємо <region> з назви файлу, який має бути у форматі 'data/gapminder_gdp_<region>.csv'.
# Розділимо рядок за допомогою методу split та роздільника `_`,
# отримаємо останній рядок зі списку, який повертає split (`<region>.csv`),
# а потім видалимо із цього рядка розширення `.csv`.
# ПРИМІТКА: модуль pathlib, описаний у наступному блоці, також пропонує
# зручні абстракції для роботи зі шляхами файлової системи і може вирішити це завдання:
# from pathlib import Path
# region = Path(filename).stem.split('_')[-1]
region = filename.split('_')[-1][:-4]
# Вилучаємо роки зі стовпців датафрейму
headings = dataframe.columns[1:]
years = headings.str.split('_').str.get(1)
# Pandas видає помилку, коли зустрічає нечислові стовпці в обчисленнях з датафреймом,
# але ми можемо вказати Pandas ігнорувати їх за допомогою параметра `numeric_only`
dataframe.mean(numeric_only=True).plot(ax=ax, label=region)
# ПРИМІТКА: інший спосіб — застосувати метод filter для вибору лише стовпців, що містять gdp у назві
# dataframe.filter(like="gdp").mean().plot(ax=ax, label=region)
# Встановлюємо заголовок та підписи
ax.set_title('ВВП на душу населення для регіонів у часі')
ax.set_xticks(range(len(years)))
ax.set_xticklabels(years)
ax.set_xlabel('Рік')
plt.tight_layout()
plt.legend()
plt.show()Робота зі шляхами до файлів та каталогів
Модуль pathlib
надає зручні інструменти для роботи з файлами та шляхами, наприклад
отримання назви файлу без його розширення. Застосування цього модуля є
особливо доцільним під час перегляду файлів і каталогів у циклах. Цей
модуль дозволяє створювати обʼєкти, які відповідають файлам та шляхам,
на відміну від звичайних рядків з іменами файлів та каталогів, які ми
бачили вище. У прикладі нижче ми створюємо об’єкт типу Path
і аналізуємо його атрибути.
PYTHON
from pathlib import Path
p = Path("data/gapminder_gdp_africa.csv")
print(p.parent)
print(p.stem)
print(p.suffix)ВИВІД
data
gapminder_gdp_africa
.csvПідказка: Перегляньте всі доступні атрибути та
методи для об’єкта типу Path за допомогою функції
dir().
- Використовуйте цикл
forдля обробки файлів, імена яких містяться у списку. - Використовуйте
glob.globдля пошуку наборів файлів, імена яких відповідають шаблону. - Використовуйте
globіforдля обробки груп файлів.
Content from Післяобідня кава
Останнє оновлення 2026-06-18 | Редагувати цю сторінку
Вправа для рефлексії
За кавою подумайте та обговоріть наступне:
- Поширений рефрен у програмній інженерії – “Не повторюйте себе”. Яким чином техніки, які ми вивчали на попередньому занятті, допомагають нам не повторюватися? Зверніть увагу, що на практиці це питання має певні нюанси й має бути збалансоване з прагненням до найпростішого можливого рішення, яке взагалі може працювати.
- Якими є плюси / мінуси створення змінної як глобальної або локальної у функції?
- В якому випадку перетворення блоку коду на функцію має сенс?
Content from Створення функцій
Останнє оновлення 2026-06-19 | Редагувати цю сторінку
Огляд
Питання
- Як створювати власні функції?
Цілі
- Знайдіть і поясніть різницю між визначенням функції та викликом функції.
- Створити функцію, яка приймає невелику фіксовану кількість вхідних аргументів і повертає єдиний результат.
Щоб програми було легше зрозуміти, розбивайте їх на функції.
- Людина може одночасно зберігати лише декілька речей у своїй робочій пам’яті.
- Розуміння складніших/більших ідей досягається шляхом осмислення та
поєднання їхніх складових.
- Компоненти в машині.
- Леми при доведенні теорем.
- Функції служать тій же меті в програмах.
- Інкапсулюють (тобто приховують) складність, щоб ми могли розглядати її як єдине “ціле”.
- Також сприяють повторному використанню кода.
- Пишемо один раз, використовуємо багаторазово.
Функція визначається за допомогою def та задається її
назвою, параметрами та блоком коду.
- Визначення нової функції починається з
def. - Далі йде назва функції.
- Назви функцій мають відповідати тим самим правилам, що й імена змінних.
- Потім параметри в дужках.
- Порожні дужки, якщо функція не приймає жодних вхідних даних.
- Ми обговоримо це детально нижче.
- Потім двокрапка.
- Потім блок коду з відступом.
Визначення функції не виконує її.
- Визначення функції не виконує її.
- Аналогічно до присвоєння значення змінній.
- Щоб виконати код функції, її необхідно викликати.
ВИВІД
Hello!Аргументи виклику функції зіставляються з параметрами, з якими вона була визначена.
- Функції найбільш корисні, коли вони можуть працювати з різними даними.
- Укажіть параметри під час визначення функції.
- Вони стають змінними під час виконання функції.
- Параметрам присвоюються значення аргументів виклику (тобто значення, передані у функцію).
- Якщо ви не називаєте аргументи під час їх використання у виклику, аргументи будуть зіставлені з параметрами в тому порядку, у якому параметри визначені у функції.
PYTHON
def print_date(year, month, day):
joined = str(year) + '/' + str(month) + '/' + str(day)
print(joined)
print_date(1871, 3, 19)ВИВІД
1871/3/19Ми також можемо назвати аргументи під час виклику, що дозволяє передавати їх у довільному порядку та підвищує читабельність виклику. В іншому випадку під час читання коду може виникнути непорозуміння, наприклад, який аргумент йде другим: місяць або день.
ВИВІД
1871/3/19- Корисна аналогія (https://twitter.com/minisciencegirl/status/693486088963272705):
()містить інгредієнти для функції, тоді як тіло містить рецепт.
Функції можуть повертати результат свого виклику за допомогою
return.
- Використовуйте
return ...для повернення результату виклику функції. - Може виникнути будь-де у функції.
- Але функції легше зрозуміти, якщо
returnзустрічається:- На початку функції для обробки особливих випадків.
- У самому кінці з остаточним результатом.
ВИВІД
average of actual values: 2.6666666666666665ВИВІД
average of empty list: None- Пам’ятайте: кожна функція щось повертає.
- Функція, яка не містить
returnявно, автоматично повертаєNone.
ВИВІД
1871/3/19
result of call is: NoneВиявлення синтаксичних помилок
- Прочитайте наведений нижче код і спробуйте знайти помилки без його запуску.
- Запустіть код і прочитайте повідомлення про помилку. Це
SyntaxErrorчиIndentationError? - Виправте помилку.
- Повторюйте кроки 2 та 3 доки не виправите всі помилки.
ВИВІД
calling <function report at 0x7fd128ff1bf8> 22.5Виклик функції завжди потребує круглі дужки, інакше повертається
адреса об’єкта функції в пам’яті. Отже, якщо ми хочемо викликати функцію
з назвою report і надати їй значення 22,5 для обробки,
виклик функції матиме такий вигляд:
ВИВІД
calling
pressure is 22.5Порядок виконання операцій
- Що не так у цьому прикладі?
PYTHON
result = print_time(11, 37, 59)
def print_time(hour, minute, second):
time_string = str(hour) + ':' + str(minute) + ':' + str(second)
print(time_string)- Після виправлення проблеми вище поясніть, чому виконання цього прикладу:
дає такий результат:
ВИВІД
11:37:59
result of call is: None- Чому результатом виклику є
None?
Проблема цього прикладу полягає в тому, що функція
print_time()визначається після виклику функції. Python не може розпізнати ім’яprint_timeоскільки воно ще не визначено і генерує помилкуNameError, тобтоNameError: name 'print_time' is not definedПерший рядок виводу
11:37:59з’являється завдяки першому рядку кодуresult = print_time(11, 37, 59). Він викликає функціюprint_timeі присвоює повернуте нею значення зміннійresult. Другий рядок є результатом наступного виклику функціїprint, який виводить вміст змінноїresult.print_time()явно не повертає значення за допомогоюreturn, тому автоматично повертаєNone.
Пошук першого від’ємного значення
Заповніть порожні поля, щоб створити функцію, яка приймає список чисел як аргумент і повертає перше від’ємне значення в списку. Що робить ваша функція, якщо список порожній? Що відбувається, якщо список не містить жодного від’ємного числа?
Виклик з іменованими аргументами
Раніше ми розглядали цю функцію:
PYTHON
def print_date(year, month, day):
joined = str(year) + '/' + str(month) + '/' + str(day)
print(joined)Ми бачили, що можна викликати функцію за допомогою *іменованих аргументів *, наприклад:
- Що друкує
print_date(day=1, month=2, year=2003)? - Коли ви раніше бачили подібний виклик функції?
- За яких умов і з якою метою доцільно використовувати іменовані аргументи при виклику функцій?
2003/2/1- Ми бачили приклади використання іменованих аргументів під час роботи
з бібліотекою pandas. Наприклад, під час читання набору даних за
допомогою
data = pd.read_csv('data/gapminder_gdp_europe.csv', index_col='country'), останній аргументindex_colє іменованим аргументом. - Використання іменованих аргументів покращує читабельність коду — з виклику функції можна побачити, які імена мають аргументи всередині функції. Це також зменшує ймовірність передачі аргументів у неправильному порядку, оскільки при використанні іменованих аргументів порядок не має значення.
Винесення блоку If/Print в окрему функцію
Наведений нижче код призначений для друку етикеток для курячих яєць. Цифрові ваги повідомляють комп’ютер про масу курячого яйця (у грамах), після чого комп’ютер друкує етикетку.
PYTHON
import random
for i in range(10):
# імітація маси курячого яйця
# маса має випадкове значення у диапазоні 70 +/- 20 грамів
mass = 70 + 20.0 * (2.0 * random.random() - 1.0)
print(mass)
# друк етикетки машиною для сортування яєць
if mass >= 85:
print("jumbo")
elif mass >= 70:
print("large")
elif mass < 70 and mass >= 55:
print("medium")
else:
print("small")Блок if, який класифікує яйця, може бути корисним в
інших ситуаціях. Щоб уникнути його повторення доцільно виділити його в
окрему функцію get_egg_label(). Переписавши програму з
використанням зазначеної функції, отримаємо такий результат:
PYTHON
# revised version
import random
for i in range(10):
# імітація маси курячого яйця
# маса має випадкове значення у диапазоні 70 +/- 20 грамів
mass = 70 + 20.0 * (2.0 * random.random() - 1.0)
print(mass, get_egg_label(mass))- Створіть функцію
print_egg_label(), яка працюватиме з новою версією програми, наведеною вище. Зверніть увагу на значення, яке повертає функціяget_egg_label(). Зразок виводу програми вище буде71.23 large. - Брудне яйце може мати масу понад 90 грамів, а зіпсоване чи розбите
яйце, ймовірно, матиме масу менше ніж 50 грамів. Змініть функцію
print_egg_label()для врахування цих умов. Можливий вивід програми:25 too light, probably spoiled.
PYTHON
def get_egg_label(mass):
# друк етикетки машиною для сортування яєць
egg_label = "Unlabelled"
if mass >= 90:
egg_label = "warning: egg might be dirty"
elif mass >= 85:
egg_label = "jumbo"
elif mass >= 70:
egg_label = "large"
elif mass < 70 and mass >= 55:
egg_label = "medium"
elif mass < 50:
egg_label = "too light, probably spoiled"
else:
egg_label = "small"
return egg_labelФункція для аналізу даних
Припустимо, що був виконаний наступний код:
PYTHON
import pandas as pd
data_asia = pd.read_csv('data/gapminder_gdp_asia.csv', index_col=0)
japan = data_asia.loc['Japan']- Заповніть наведені нижче пропуски. Результатом має бути середній ВВП Японії за роками, які присутні у наборі даних та належать до 1980-х.
PYTHON
year = 1983
gdp_decade = 'gdpPercap_' + str(year // ____)
avg = (japan.loc[gdp_decade + ___] + japan.loc[gdp_decade + ___]) / 2- Перетворіть наведений вище код в окрему функцію.
PYTHON
def avg_gdp_in_decade(country, continent, year):
data_countries = pd.read_csv('data/gapminder_gdp_'+___+'.csv',delimiter=',',index_col=0)
____
____
____
return avg- Як узагальнити функцію, якщо роки у стовпцях заздалегідь невідомі? Наприклад, якщо набір даних також містить роки, що закінчуються на 1 та 9 для кожного десятиліття? (Підказка: використовуйте стовпці, щоб відфільтрувати їх за десятиліттям.)
- Середній ВВП Японії по відзвітованих роках з 1980-тих обчислюється за допомогою:
PYTHON
year = 1983
gdp_decade = 'gdpPercap_' + str(year // 10)
avg = (japan.loc[gdp_decade + '2'] + japan.loc[gdp_decade + '7']) / 2- Цей код як функція:
PYTHON
def avg_gdp_in_decade(country, continent, year):
data_countries = pd.read_csv('data/gapminder_gdp_' + continent + '.csv', index_col=0)
c = data_countries.loc[country]
gdp_decade = 'gdpPercap_' + str(year // 10)
avg = (c.loc[gdp_decade + '2'] + c.loc[gdp_decade + '7'])/2
return avg- Щоб отримати середнє значення за відповідні роки, нам потрібно застосувати цикл:
PYTHON
def avg_gdp_in_decade(country, continent, year):
data_countries = pd.read_csv('data/gapminder_gdp_' + continent + '.csv', index_col=0)
c = data_countries.loc[country]
gdp_decade = 'gdpPercap_' + str(year // 10)
total = 0.0
num_years = 0
for yr_header in c.index: # індекс c містить звітні роки
if yr_header.startswith(gdp_decade):
total = total + c.loc[yr_header]
num_years = num_years + 1
return total/num_yearsЦя функція тепер може викликатися наступним чином:
ВИВІД
20880.023800000003Моделювання динамічної системи
У математиці динамічна система - це система, у якій функція описує залежність розташування точки в геометричному просторі від часу. Канонічний приклад динамічної системи - це логістичне відображення, тобто модель зростання, яка обчислює нову щільність популяції (від 0 до 1) на основі її поточного значення. В цій моделі час приймає дискретні значення 0, 1, 2, … (тобто змінюється кроками, а не плавно)
- Визначте функцію під назвою
logistic_map, яка приймає два аргументи:x, що представляє популяцію в момент часуt, та параметрr=1. Ця функція має повертати значення, що представляє стан системи (популяції) у момент часуt + 1, використовуючи наступну функцію:
f(t+1) = r * f(t) * [1 - f(t)]
Використовуючи цикл
forабоwhile, повторюйте виклик функціїlogistic_map, визначеної в частині 1. Початкове значення густини популяції становить 0.5, а часовий інтервал —t_final = 10. Зберігайте проміжні результати в списку, щоб після завершення циклу ви накопичили послідовність значень, що представляють стан системи в моменти часуt = [0,1,...,t_final](11 значень в цілому). Виведіть цей список, щоб побачити, як змінюється популяція з часом.Помістить цей цикл у функцію під назвою
iterate, яка отримує три вхідні параметри: початкове значення густини популяції,t_finalтаr. Функція має повертати список значень, що представляють стан системи в моменти часуt = [0,1,...,t_final]. Виконайте цю функцію для періодівt_final = 100та1000, і виведіть деякі з отриманих значень. Чи рухається популяція до стабільного стану?
PYTHON
initial_population = 0.5
t_final = 10
r = 1.0
population = [initial_population]
for t in range(t_final):
population.append( logistic_map(population[t], r) )PYTHON
def iterate(initial_population, t_final, r):
population = [initial_population]
for t in range(t_final):
population.append( logistic_map(population[t], r) )
return population
for period in (10, 100, 1000):
population = iterate(0.5, period, 1)
print(population[-1])ВИВІД
0.06945089389714401
0.009395779870614648
0.0009913908614406382Здається, популяція наближається до нуля.
Використання функцій з умовними операторами в Pandas
Функції часто містять перевірку умов. Нижче наведено короткий приклад, що визначає належність аргументу до певного квартиля на основі попередньо заданих граничних значень квартилів.
PYTHON
def calculate_life_quartile(exp):
if exp < 58.41:
# Це спостереження знаходиться в першому квартилі
return 1
elif exp >= 58.41 and exp < 67.05:
# Це спостереження знаходиться у другому квартилі
return 2
elif exp >= 67.05 and exp < 71.70:
# Це спостереження знаходиться у третьому квартилі
return 3
elif exp >= 71.70:
# Це спостереження знаходиться в четвертому квартилі
return 4
else:
# Це спостереження містить невірні дані
return None
calculate_life_quartile(62.5)ВИВІД
2Зазвичай така функція використовується всередині циклу
for. Але Pandas має інший, більш ефективний спосіб робити
те саме - застосування функції до датафрейму або його частини.
Розглянемо приклад, використовуючи наведене вище визначення функції.
PYTHON
data = pd.read_csv('data/gapminder_all.csv')
data['life_qrtl'] = data['lifeExp_1952'].apply(calculate_life_quartile)У другому рядку коду багато цікавого, тож розберімо його по частинах.
Праворуч від = ми починаємо з data['lifeExp']
— це стовпець датафрейму data, що має мітку
lifExp. Ми використовуємо apply(), щоб
застосувати функцію calculate_life_quartile до усіх значень
цього стовпця.
- Розбивайте програми на функції, щоб їх було легше зрозуміти.
- Функції визначаються за допомогою
defз назвою, параметрами та блоком коду. - Визначення функції не запускає її.
- Аргументи виклику функції зіставляються з її визначеними параметрами.
- Функції можуть повертати результат свого виклику за допомогою
return.
Content from Область видимості змінної
Останнє оновлення 2026-07-01 | Редагувати цю сторінку
Огляд
Питання
- Як насправді працюють виклики функцій?
- Як можна визначити, де виникають помилки?
Цілі
- Розрізняти локальні та глобальні змінні.
- Розглядання параметрів як локальних змінних.
- Аналіз повідомлень про помилки (traceback) та визначення файлу, функції й номера рядка, де виникла помилка, тип помилки та текстове повідомлення про неї.
Область видимості змінної - це частина програми, яка може “бачити” цю зміну.
- Кількість змістовних імен для змінних є обмеженою.
- Користувачі функцій не повинні турбуватися про те, які імена змінних обрав автор функції.
- Автори функцій не повинні турбуватися про те, які імена змінних використовує код, що здійснює виклик функції.
- Частина програми, в якій змінна є видимою, називається її областю.
-
pressure– це глобальна змінна.- Визначається поза будь-якою конкретною функцією.
- Є видимою у будь-якому місці програми.
- Змінні
tтаtemperatureє локальними у межах функціїadjust.- Визначені всередині функції.
- Не є видимими у головній програмі.
- Нагадування: параметр функції – це змінна, якій автоматично присвоюється значення під час виклику функції.
ВИВІД
adjusted: 0.01238691049085659ПОМИЛКА
Traceback (most recent call last):
File "/Users/swcarpentry/foo.py", line 8, in <module>
print('temperature after call:', temperature)
NameError: name 'temperature' is not definedВикористання локальних і глобальних змінних
Читання повідомлень про помилки
Прочитайте наведене нижче повідомлення про помилку та визначте наступне:
- Скільки рівнів вкладеності відображає це повідомлення?
- Як називається файл, у якому сталася помилка?
- Як називається функція, у якій сталася помилка?
- В якому рядку цієї функції виникла помилка?
- Який тип помилки?
- Яке повідомлення про помилку?
ПОМИЛКА
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-2-e4c4cbafeeb5> in <module>()
1 import errors_02
----> 2 errors_02.print_friday_message()
/Users/ghopper/thesis/code/errors_02.py in print_friday_message()
13
14 def print_friday_message():
---> 15 print_message("Friday")
/Users/ghopper/thesis/code/errors_02.py in print_message(day)
9 "sunday": "Aw, the weekend is almost over."
10 }
---> 11 print(messages[day])
12
13
KeyError: 'Friday'- Три рівні.
errors_02.pyprint_message- Рядок 11
-
KeyError. Ці помилки виникають при спробі звернутися до ключа, який не існує (зазвичай в структурі даних на кшталт словника). Докладніше проKeyErrorта інші вбудовані винятки див. документацію Python. KeyError: 'Friday'
- Область видимості змінної - це частина програми, яка може “бачити” цю зміну.
Content from Стиль програмування
Останнє оновлення 2026-07-01 | Редагувати цю сторінку
Огляд
Питання
- Як я можу зробити свої програми більш читабельними?
- Як більшість програмістів форматують свій код?
- Яким чином програми можуть самостійно перевіряти, що вони працюють правильно?
Цілі
- Дотримуйтесь основних правил стилю кодування.
- Виконуйте рефакторинг односторінкових програм, щоб зробити їх більш читабельними та обґрунтувати зміни.
- Дотримуйтесь стандартів кодування, прийнятих у спільноті користувачів Python (PEP-8).
Стиль кодування
Дотримання послідовного стилю кодування сприяє кращому розумінню коду іншими особами (зокрема нами самими в майбутньому). Код читається набагато частіше, ніж пишеться, і, як стверджує Дзен Python, “читабельність має значення”. Стандартний стиль для Python було запропоновано в одному з перших документів PEP (Python Enhancement Proposal), PEP8.
Варто відзначити такі моменти:
- документуйте ваш код, чітко зазначаючи припущення, внутрішні алгоритми, очікувані вхідні та вихідні дані тощо
- використовуйте зрозумілі, змістовні назви змінних
- для відступів використовуйте пробіли, а не табуляцію (табуляція може призводити до проблем у різних текстових редакторах, операційних системах і системах контролю версій)
Дотримуйтеся стандартного стилю Python у своєму коді.
-
PEP8:
рекомендації зі стилю Python, що описують такі аспекти, як назви
змінних, відступи в коді, структуру операторів
importтощо. Дотримання стандарту PEP8 сприяє кращому розумінню коду іншими розробниками Python, а також розумінню того, яким має бути формат їхнього внеску. - Щоб перевірити свій код на відповідність PEP8, можна використовувати [застосунок pycodestyle](https://pypi.org/project/pycodestyle/, який повідомляє про порушення стилю. Такі інструменти, як black code formatter, можуть автоматично виправити форматування коду відповідно до PEP8 (для Jupyter notebook існує nb_black).
- Деякі групи та організації застосовують інші стандарти стилю, відмінні від PEP8. Наприклад, настанови Google зі стилю Python містять дещо інші рекомендації. Google створила застосунок під назвою yapf, який може допомогти вам форматувати код відповідно до стилю Google або PEP8.
- Щодо стилю кодування, ключовим фактором є послідовність. Оберіть стиль для свого проєкту (PEP8, стиль Google або інший) і подбайте про те, щоб ви та інші учасники команди дотримувалися його. Послідовність у проєкті зазвичай впливає сильніше, ніж вибір конкретного стилю. Послідовний стиль полегшує читання та розуміння коду іншими розробниками, а також вами самими в майбутньому.
Застосовуйте твердження для виявлення внутрішніх помилок.
Твердження (assertions) — простий, але дієвий спосіб переконатися, що контекст виконання коду відповідає вашим очікуванням.
PYTHON
def calc_bulk_density(mass, volume):
'''Повертає щільність сухої речовини = маса / об'єм.'''
assert volume > 0
return mass / volumeЯкщо твердження має значення False, інтерпретатор Python
викличе виняток AssertionError під час виконання програми.
Вихідний код виразу, що спричинив помилку, виводиться як частина
повідомлення про помилку. Щоб ігнорувати твердження у вашому коді,
запустіть інтерпретатор з опцією ‘-O’ (оптимізація). Твердження повинні
містити лише прості перевірки та ніколи не змінювати стан програми.
Наприклад, твердження ніколи не повинне містити присвоєння.
Використовуйте рядки документації (docstrings) для створення вбудованої довідки.
У випадку, коли першим елементом тіла функції є рядок символів, який
не присвоєно жодній змінній, Python автоматично прив’язує його до
функції у вигляді атрибута. Цей атрибут стає доступним за допомогою
вбудованої функції help. Цей рядок, що забезпечує
документацію, також відомий як docstring.
PYTHON
def average(values):
"Повертає середнє значення або None, якщо значення не надано."
if len(values) == 0:
return None
return sum(values) / len(values)
help(average)ВИВІД
Help on function average in module __main__:
average(values)
Повертає середнє значення або None, якщо значення не надано.Що буде показано?
Виділіть в коді нижче рядки, які будуть доступні як онлайн-довідка. Чи є рядки, які мають бути доступні, але не будуть зображатися? Чи призведе якийсь із рядків до синтаксичної помилки або помилки виконання?
PYTHON
"Знаходить максимальну відстань редагування між кількома послідовностями."
# Знаходить максимальну відстань між усіма послідовностями.
def overall_max(sequences):
'''Визначає загальну максимальну відстань редагування.'''
highest = 0
for left in sequences:
for right in sequences:
'''Уникаємо порівняння послідовності із самою собою.''
if left != right:
this = edit_distance(left, right)
highest = max(highest, this)
# Повертаємо результат.
return highestСтворюємо документацію
Застосовуйте коментарі для опису та пояснення розділів коду або окремих рядків, що можуть бути неінтуїтивно зрозумілими для інших. Вони є особливо корисними для будь-кого, хто матиме потребу зрозуміти та відредагувати ваш код у майбутньому, зокрема для вас самих.
Застосовуйте рядки документації для опису допустимих вхідних даних та
очікуваних вихідних даних методу чи класу, а також їхнього призначення,
припущень і передбачуваної поведінки. Рядки документації зображаються,
коли користувач викликає вбудований метод help для вашого
методу або класу.
Перетворіть коментар у наступній функції на рядок документації та
переконайтеся, що команда help правильно його
відображає.
Зробіть цей код більш зрозумілим
- Прочитайте цю коротку програму та спробуйте передбачити, що вона робить.
- Запустіть її: наскільки точним було ваше передбачення?
- Переробіть програму, щоб зробити її більш читабельною. Не забувайте запускати її після кожної зміни, щоб переконатися, що її поведінка не змінилася.
- Порівняйте свій код з результатом когось іншого. Що ви зробили так само? Що ви зробили інакше і чому?
Ось один з варіантів рішення.
PYTHON
def string_machine(input_string, iterations):
"""
На вхід поступає input_string. Далі генерується новий рядок із символами "-" та "*",
що відповідають символам, які мають або не мають ідентичні сусідні
символи, відповідно. Ця процедура повторюється з отриманими рядками з
попереднього кроку задану кількість разів.
"""
print(input_string)
input_string_length = len(input_string)
old = input_string
for i in range(iterations):
new = ''
# перебираються символи в рядку old.
for j in range(input_string_length):
left = j-1
right = (j+1) % input_string_length # перший символ є суміжним для останнього
if old[left] == old[right]:
new = new + '-'
else:
new = new + '*'
print(new)
# Рядок new зберігається як old
old = new
string_machine('et cetera', 10)ВИВІД
et cetera
*****-***
----*-*--
---*---*-
--*-*-*-*
**-------
***-----*
--**---**
*****-***
----*-*--
---*---*-- Дотримуйтеся стандартного стилю Python у своєму коді.
- Використовуйте рядки документів для надання вбудованої довідки.
Content from Підбиття підсумків
Останнє оновлення 2026-07-02 | Редагувати цю сторінку
Огляд
Питання
- Що саме ми вивчили?
- Що ще існує в екосистемі мови Python, і де це можна знайти?
Цілі
- Назвіть і знайдіть сайти наукової спільноти Python, присвячені програмному забезпеченню, семінарам і допомозі користувачам.
Леслі Лампорт якось сказав: “Письмо — це спосіб природи показати вам хаотичність вашого мислення”. Те саме стосується програмування: багато речей, які здаються очевидними, коли ми думаємо про них, виявляються зовсім іншим, коли ми маємо точно їх пояснити.
Навколо Python сформувалася велика й різноманітна спільнота користувачів в академічних і промислових колах.
Документація з Python 3 охоплює основні поняття мови програмування та стандартну бібліотеку Python.
PyCon є найбільшою щорічною конференцією для спільноти Python.
SciPy - пакет, який надає багато наукових інструментів. Це також назва серії щорічних конференцій.
Jupyter - це офіційний сайт проєкту Jupyter.
Pandas - це офіційний сайт бібліотеки Pandas для роботи з даними.
Розділ Stack Overflow, приcвячений Python, може бути корисним, так само як і розділи, присвячені NumPy, SciPy, та Pandas.
- Навколо Python сформувалася велика й різноманітна спільнота користувачів в академічних і промислових колах.
Content from Зворотний зв'язок
Останнє оновлення 2026-06-18 | Редагувати цю сторінку
Огляд
Питання
- Як пройшов урок?
Цілі
- Зібрати відгуки про заняття
Зберіть відгуки про заняття
- Ми постійно прагнемо покращити цей курс.